参考资料:B站@左美美_ 相关视频
数据倾斜定义
任务进度长时间维持在99%,查看任务监异页面,发现只有少量1个或几个reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多,最长时长远大于平均时长。
数据倾斜产生原因
map输出数据按keyHash的分配到reduce中,由于key分布不均匀、业务数据本身的特性、建表时考虑不周、某些SQL语句本身就有数据倾斜等原因,造成的reduce上的数据量差异过大,所以如何将数据均匀的分配到各个reduce中,就是解决数据倾斜的根本所在。
Key为空引起数据倾斜
倾斜原因
join的key值发生倾斜,key值包含很多空值或是异常值。
解决方案
对值为空的key进行打散,为空key赋一个随机的值,使得key值为空的数据随机均匀地分布到不同的reducer上。
测试案例
设置多个reduce任务
set mapreduce.job.reduces = 5;
两张大表join,做全连接
|
|
备注:nvl()为空值转换函数,rand()为随机函数。也可以使用ifnull()、coalesce()
group by 引起数据倾斜
倾斜原因
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。
解决方案
并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
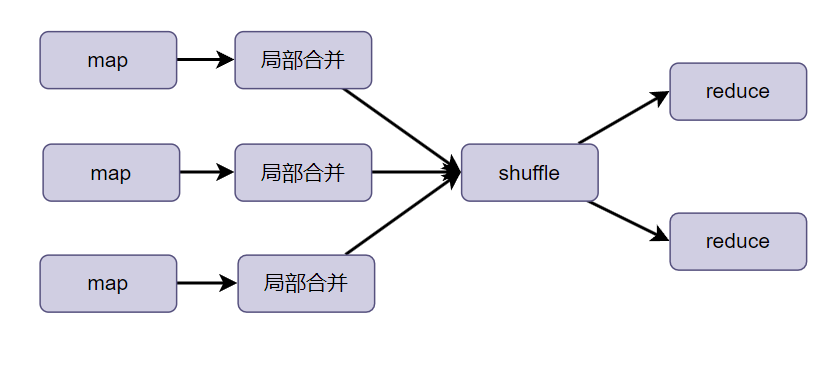
实现方式1
1)是否在Map端进行聚合,默认为True(使用Combiner局部合并)
set hive.map.aggr = true;
2)设置map端预聚合的行数阈值
set hive.groupby.mapaggr.checkinterval=100000;
实现方式2
有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skelindata= true;
当遇到数据倾斜时,groupby会启动两个MR job。第一个job会将map端数据随机输入reducer,每个reducer做部分聚合,相同的key就会分布在不同的reducer中。第二个job再将前面预处理过的数据按key聚合并输出结果,这样就起到了均衡的效果。
测试案例
|
|
|
|
count distinct引起数据倾斜
倾斜原因
count distinct聚合时存在大量特殊值,比如存在大量值为NULL或空的记录。
解决方案
做count distinct时,将值为空的情况单独处理。
1)如果只是统计去重后的记录数,可以不用处理空值,先把空值过滤掉,然后在最后结果中加1即可
2)如果还包含其他计算,需要进行groupby操作,先将值为空的记录单独处理,然后再跟其他计算结果union操作。
join操作引起数据倾斜
大表join小表(hive旧版本)
新版本(Hive3)已经自动自动优化
1)产生原因
业务数据本身就存在key分布不均匀的情况,一般情况会产生数据倾斜
2)解决方式
使用map join让小的维度表先进内存,在map端完成join
3)实现原理
使用map join,直接在map端就完成表的join操作,进入map端的数据都是经过split得到的,没有根据key分区这一操作,所以数据都是相对均匀地分布在每个maptask中的,所以就不会产生数据倾斜。
大表join大表
1)产生原因
业务数据本身的特性,导致两个表都是大表。
2)解决方式
业务消减
3)实现原理
业务数据有数据倾斜的风险,但是这些导致数据倾斜风险的key一般都是无效的,如uid为空,因为uid为空的记录是没有意义的。
所以当业务数据很大,但是数据中的大部分(一般都是80%)可能都是无效数据,那么就可以在join时过滤掉空值uid,没有了这些无效数据,自然就不存在这么大量集中的key,数据倾斜的风险就会消失。