2025/01/13 腾讯音乐运维一面
Linux
Linux启动顺序
BIOS/UEFI阶段
BIOS(Basic Input Output System):基本输入输出系统。它是一组固化到计算机内主板上一个daoROM芯片上的程序,它保存着计算机最重要的基本输入输出的程序、系统设置信息、开机后自检程序和系统自启动程序。 其主要功能是为计算机提供最底层的、最直接的硬件设置和控制。BIOS应该是连接软件程序与硬件设备的一座"桥梁",负责解决硬件的即时要求。简单地说,BIOS就是一个加载在计算机主板上最基础的一段程序,负责最基础的硬件控制和设置。
MBR(Master Boot Record):主引导程序,是分区计算器大容量存储设备(如固定硬盘或移动硬盘)的第一个块中的一种引导扇区。
加载位于主板ROM中地址0xFFFF0的BIOS信息,主要包括系统BIOS和显卡BIOS;进行POST自检,检查CPU、内存、主板等硬件;建立终端向量表和中断服务程序;检测可引导设备;加载MBR(主引导程序)的前446字节到内存0x7c00处。
注:老电脑用MBR,较新的电脑,2017年之后的系统如Ubuntu17.04都默认使用GPT+UEFI组合。UEFI最大的好处就是启动方便,有图形化界面。
目前主板多设置成三种启动模式,即:Auto、UEFI、Legacy。在设置启动时,带有UEFI的BIOS还提供了启动选项供大家选择以何种方式启,各种模式含义如下:
Auto(自动)/Both:自动按照启动设备列表中的顺序启动,优先采用UEFI方式;
UEFI only(仅UEFI):只选择具备UEFI启动条件的设备启动;
Legacy only(仅Legacy):只选择具备Legacy启动条件的设备启动。
简单的来说uefi启动是新一代的bios,功能更加强大,而且它是以图形图像模式显示,让用户更便捷的直观操作。
MBR最大支持2TB硬盘;最多支持4个主分区,或3个主分区+1个扩展分区;扩展分区可以包含多个逻辑分区;分区表只有一份,易损坏;启动代码占446字节,分区表占64字节;兼容传统BIOS系统 GPT (GUID Partition Table)支持超过2TB的硬盘(最大18EB);支持最多128个分区(理论上可更多);分区表有主副两份,更安全;每个分区都有全球唯一标识符(GUID);支持更多分区类型;需要UEFI启动支持
Boot Loader阶段
显示内核选择菜单;加载选定的内核镜像到内存;加载initramfs到内存;然后将控制权移交给内核
Kernel初始化阶段
系统读取内存映像,并进行解压缩操作。此时,屏幕一般会输出“Uncompressing Linux”的提示。当解压缩内核完成后,屏幕输出“OK, booting the kernel”。 系统将解压后的内核放置在内存之中,并调用start_kernel()函数来启动一系列的初始化函数并初始化各种设备,完成Linux核心环境的建立。 然后系统会初始化CPU、内存、设备驱动;挂载根文件系统;运行/sbin/init(PID 1)
Init进程(systemd)阶段
Unit:systemd管理的基本单元,包括
service服务、socket进程间通信套接字、target启动目标(类似于运行级别)、mount文件系统挂载点、device设备文件、timer定时器。配置文件优先级依次是:/etc/systemd/system/系统管理员创建的配置,优先级最高;/run/systemd/system/运行时配置文件;/usr/lib/systemd/system/软件包安装的默认配置。
读取默认target配置文件;分析unit间依赖关系;激活系统服务;准备各类daemon进程;准备用户环境。
备注:系统级自启动程序就是在这时候启动的,如通过apt安装的Mysql、Docker。
用户空间阶段
依次读取/etc/profile系统环境变量、 ~/.bashrc用户环境变量、 /etc/passwd用户账户信息、 /etc/shadow用户密码信息
启动显示管理器,加载桌面环境,准备终端设备;等待用户登录
备注:用户级自启动程序在读取~/.bashrc后自动执行,也就是说想要设置用户级自启动命令可以将启动命令写入到~/.bashrc中
Linux开机自启动
Linux有三种级别的开机自启动:
系统级别
通过apt包管理器安装的包默认就是这种级别的开机自启。
可以通过 sudo systemctl enable mysql来启用开机自启(sudo systemctl disable mysql为关闭开机自启命令)。
除了包管理器,还可以自己制作service来实现,以nginx为例:
- 在
/etc/systemd/system/下创建nginx.service文件
|
|
写入如下内容:
|
|
- 设置开机自启
|
|
用户级别
将需要自启动的命令写入~/.bashrc中,即可实现用户级开机自启。具体操作时如果命令较为简单,比如使用alias给命令指定别名或者ulimit -n 65536修改最大打开文件句柄数(我的Ubuntu不知道为什么永久修改怎么也修改不成功,只能通过这种方式曲线救国),就可以直接把命令写到~/.bashrc中。如果命令比较复杂,可以考虑将命令打包成脚本,然后在~/.bashrc中执行启动脚本的命令。
桌面级别
大体步骤类似系统级自启动:切换到/etc/xdg/autostart/目录,创建后缀为desktop的文件,编辑并保存。重启生效。
数据库
MySQL主从复制配置过程,宕机恢复
参考资料:https://xiaolincoding.com/mysql/log/how_update.html#%E4%B8%BB%E4%BB%8E%E5%A4%8D%E5%88%B6%E6%98%AF%E6%80%8E%E4%B9%88%E5%AE%9E%E7%8E%B0
主从复制可以用来做数据库的实时备份,保证数据的完整性;也可以做读写分离,提升数据库系统整体的读写性能。
主从复制原理:
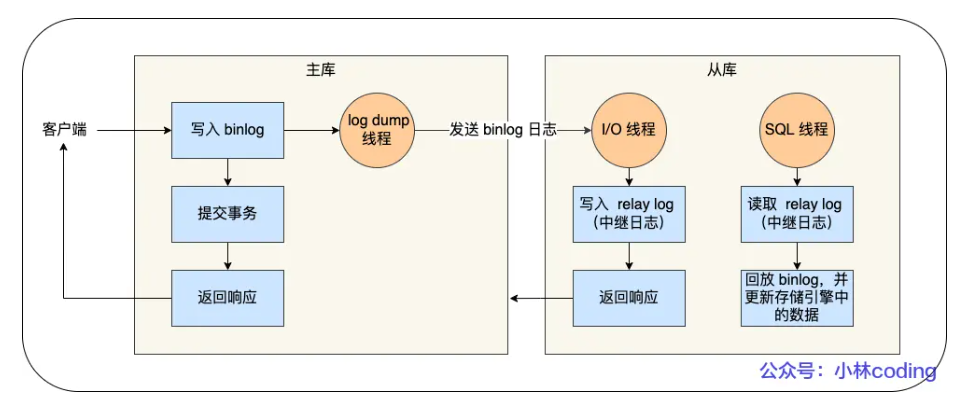 MySQL集群的主从复制过程梳理成3个阶段:
MySQL集群的主从复制过程梳理成3个阶段:
- 写入 Binlog:主库写 binlog 日志,提交事务,并更新本地存储数据。
- 同步 Binlog:把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存日志中。
- 回放 Binlog:回放 binlog,并更新存储引l擎中的数据。 具体详细过程如下:
- MySQL 主库在收到客户端提交事务的请求之后,会先写入binlog,再提交事务,更新存储引擎中的数 据,事务提交完成后,返回给客户端"操作成功"的响应。
- 从库会创建一个专门的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog 日志,再把 binlog 信息写入 relay log 的中继日志里,再返回给主库"复制成功"的响应。
- 从库会创建一个用于回放 binlog 的线程,去读 relay log 中继日志,然后回放 binlog 更新存储引擎中
的数据,最终实现主从的数据一致性。
在完成主从复制之后,你就可以在写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者
锁记录,也不会影响读请求的执行。
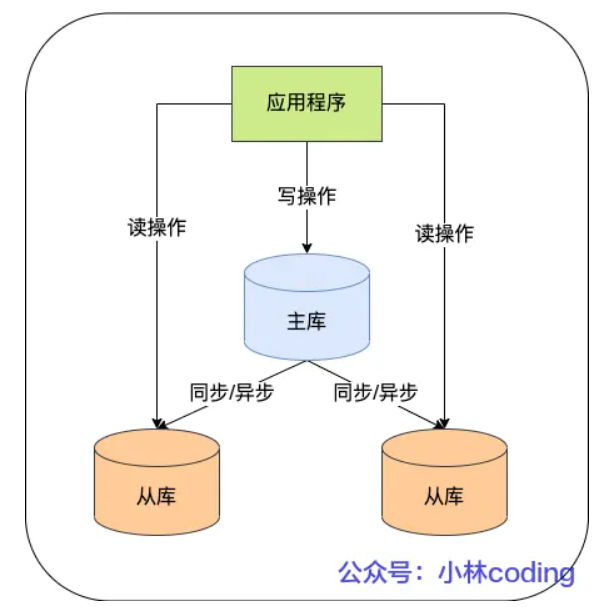
主从复制配置过程
参考资料:https://www.cnblogs.com/nulige/articles/9273537.html 两台机器都操作,确保 server-id 要不同,通常主ID要小于从ID。一定注意。
MySQL binlog格式
binlog 是 MySQL 中的一种重要日志类型,用于记录所有的DDL和DML操作(不包括数据查询语句)。它主要用于数据恢复和主从复制。Binlog有三种模式:STATEMENT(语句模式)、ROW(行模式) 和 MIXED(混合模式)
STATEMENT模式:基于SQL语句的复制(Statement-Based Replication, SBR),每一条修改数据的SQL语句都会记录到binlog中
- 优点:减少日志量:不需要记录每一行数据的变化,减少了磁盘IO,提高了性能
- 缺点:数据不一致:在某些情况下,主从库的数据可能会不一致。例如,使用 uuid() 函数时,每次执行都会生成不同的值;自增字段在执行时可能得到错误的值
ROW模式:基于行的复制(Row-Based Replication, RBR),不记录SQL语句的上下文信息,仅记录哪条数据被修改了
- 优点:准确复制:不会出现存储过程、函数或触发器调用无法正确复制的问题
- 缺点:日志量大:尤其是在执行批量更新或删除操作时,会产生大量日志,影响IO性能
MIXED模式:是前两种模式的混合体(Mixed-Based Replication, MBR),MySQL会根据具体的SQL语句选择使用STATEMENT或ROW模式。 一般情况下,使用STATEMENT模式保存binlog,对于无法准确复制的操作则使用ROW模式
配置和查看Binlog
要开启和配置Binlog,可以修改MySQL的配置文件 my.cnf
|
|
查看Binlog日志可以使用 mysqlbinlog 工具
|
|
或者使用SQL命令查看事件:
|
|
通过合理选择和配置Binlog模式,可以有效提高MySQL的性能和数据一致性
MySQL 备份,逻辑备份与物理备份
MySQL的物理备份和逻辑备份的主要区别在于备份文件的形式和备份恢复的灵活性。 物理备份直接复制数据库的二进制文件(binlog),备份文件较大,恢复时只能在相同架构的MySQL服务器上使用。 逻辑备份将数据库导出为SQL语句的形式,备份文件较小,恢复时可跨平台使用,也可以进行数据的修改和筛选。
容器化
k8s移动pod
参考资料:https://blog.csdn.net/yanggd1987/article/details/108139436
k8s集群中的node节点要升级内存,以应对服务迁入、pod扩缩容导致的资源短缺,需要对node节点进行停机维护。此时就需要对pod进行迁移。
默认迁移
当node节点关机后,k8s集群并没有立刻发生任何自动迁移动作,如果该node节点上的副本数为1,则会出现服务中断的情况。其实事实并非如此,k8s在等待5分钟后,会自动将停机node节点上的pod自动迁移到其他node节点上。
|
|
从以上过程看出,停机node节点上的pod在5分钟后先终止再重建,直到pod在新节点启动并由readiness探针检测正常后并处于1\1 Running状态才可以正式对外提供服务。因此服务中断时间=停机等待5分钟时间+重建时间+服务启动时间+readiness探针检测正常时间。
为什么pod在5分钟后开始迁移呢? 此时需要涉及到k8s中的Taint(污点)和 Toleration(容忍),这是从Kubernetes 1.6开始提供的高级调度功能。Taint和Toleration相互配合,可以避免pod被分配到不合适的节点上。每个节点上都可以应用一个或多个Taint,这表示对于那些不能容忍Taint的pod,是不会被该节点接受的。如果将Toleration应用于pod上,则表示这些pod可以(但不要求)被调度到具有匹配Taint的节点上。
|
|
此时pod的Tolerations 默认对于具有相应Taint的node节点容忍时间为300s,超过此时间pod将会被驱逐到其他可用node节点上。因此5分钟后node节点上所有的pod重新被调度,在此期间服务是中断的。
手动迁移
默认的pod迁移无法避免服务中断,那么我们在node节点停机前,我们可以手动迁移。 为避免等待默认的5分钟,我们还可以使用cordon、drain、uncordor三个命令实现节点的主动维护。此时需要用到以下三个命令:
cordon:标记节点不可调度,后续新的pod不会被调度到此节点,但是该节点上的pod可以正常对外服务;drain:驱逐节点上的pod至其他可调度节点;uncordon:标记节点可调度 具体操作如下:
|
|
此时与默认迁移不同的是,pod会先重建再终止,此时的服务中断时间=重建时间+服务启动时间+readiness探针检测正常时间,必须等到1/1 Running服务才会正常。因此在单副本时迁移时,服务中断是不可避免的。
平滑迁移
要做到平滑迁移就需要用的pdb(PodDisruptionBudget),即主动驱逐保护。无论是默认迁移和手动迁移,都会导致服务中断,而pdb能可以实现节点维护期间不低于一定数量的pod正常运行,从而保证服务的可用性。
在仍以helloworld为例,由于只有一个副本,因此需要保证维护期间这个副本在迁移完成后,才会终止。
|
|
本次驱逐,由于helloworld始终保持有一个pod在提供服务,因此服务是不中断的。 最后将副本数可以调节为1并将node节点调整为可调度,维护完毕。
总结:通过简单了解了Taint(污点)和 Toleration(容忍)作用,我们既可以通过设置tolerationSeconds来缩短等待时间,也可以自行定义匹配规则实现符合实际情况的调度规则。
另外还要注意先重建再终止和先终止再重建,在此过程中服务启动时间和探针检测时间决定你的服务中断时间。
k8s镜像拉取配置参数及优先级
参考:https://www.cnblogs.com/leojazz/p/18686403
在 Kubernetes(简称 K8s)中,容器镜像的更新行为主要由 imagePullPolicy 参数控制。该策略决定了 Kubernetes 在启动或重启容器时是否从镜像仓库拉取新的镜像版本。常见的镜像更新策略有三种:
- Always
如果容器的
imagePullPolicy设置为 Always,每次创建 Pod 或者重启容器时,Kubelet 都会从镜像仓库拉取最新的镜像版本。这对于使用 latest 标签或者希望始终获取最新镜像的场景非常有用,但在生产环境中应谨慎使用,因为 latest 标签的镜像内容可能会随时变化,导致版本不一致或潜在的不稳定。
建议: 在生产环境中避免直接使用 latest 标签,使用明确的版本号(如 v1.0.1)来确保一致性,并记录镜像版本历史以便于追踪和排查问题。
- IfNotPresent(默认值)
当
imagePullPolicy设置为 IfNotPresent 时,如果本地节点上已经存在该镜像,则 Kubelet 不会尝试从镜像仓库拉取镜像;仅当本地不存在该镜像时,Kubelet 才会去远程仓库拉取镜像。通常,使用带有明确版本标签(如 v1.0)的镜像时,推荐使用此策略,以避免不必要的镜像拉取。
注意: 默认情况下,如果镜像标签是 latest,imagePullPolicy 会自动设置为 Always;如果是版本号标签(如 v1.0),则默认使用 IfNotPresent。
- Never
如果
imagePullPolicy设置为 Never,无论本地是否存在该镜像,Kubelet 都不会尝试从镜像仓库拉取镜像,而是始终使用本地已有的镜像。这种策略适用于不希望自动升级镜像版本,且希望始终使用特定版本的场景。
更新应用镜像的常见方法 在 Kubernetes 中,更新应用镜像的常见方法是通过修改 Deployment、StatefulSet 等控制器中定义的 Pod 模板内的镜像版本,然后执行 kubectl apply 命令将更改推送到集群,触发滚动更新。
滚动更新的过程中,Kubernetes 会逐步替换旧的容器实例,确保服务的持续可用性。您可以使用以下命令来更新镜像版本:
示例:更新 Deployment 中的镜像 假设我们有一个名为 example-deployment 的 Deployment,其中定义了一个容器镜像 myapp:v1.0。我们将镜像版本更新为 myapp:v2.0,并通过 kubectl apply 命令触发更新。
修改 Deployment 配置文件 deployment.yaml 中的镜像版本:
|
|
执行 kubectl apply 命令将变更推送到集群: kubectl apply -f deployment.yaml 在执行该命令后,Kubernetes 会根据定义的镜像更新策略(例如,imagePullPolicy: IfNotPresent)决定是否从仓库拉取新的镜像,并按滚动更新的方式逐步替换旧版本的容器实例。
滚动更新控制 在滚动更新过程中,您还可以通过以下参数控制更新过程的行为:
maxUnavailable:定义更新过程中允许不可用的最大 Pod 数量,控制更新期间服务的最小可用性。maxSurge:定义在更新过程中可以超出期望副本数的最大 Pod 数量,帮助提升更新的速度。 合理设置这两个参数可以在保证服务可用性的同时加速或控制更新过程。例如:
|
|
通过设置这些参数,您可以精细控制容器的滚动更新行为,以平衡服务可用性和更新速度。
这种修订版本提供了更为清晰的策略解释、更新的实践方法和对滚动更新的详细控制,适用于生产环境中的实际操作。
k8s镜像仓库
k8s镜像仓库分为远程仓库和本地仓库。本地仓库就是存储在本机的镜像文件,可以通过工具(如Docker Registry、Harbor)搭建,用于管理和分发镜像;
由于 Kubernetes 使用的是容器运行时(如 containerd),直接在 Docker 中构建的镜像无法直接被 Kubernetes 使用。需要将镜像导入到对应的容器运行时中。
|
|
- Kubernetes 较新版本(1.24+)已移除对 Docker 的支持,转为使用 containerd 或 CRI-O。
- 不同运行时的镜像存储路径如下:
- Docker:
/var/lib/docker - containerd:
/var/lib/containerd - CRI-O:
/var/lib/containers
- 如果需要使用本地镜像,需根据运行时类型将镜像导入到对应的存储系统中,例如使用 ctr 或 crictl。 Kubernetes 配置文件中需设置 imagePullPolicy 为 Never,并确保所有节点都加载了本地镜像。
远程仓库
-
公共镜像仓库: 这些仓库通常是开放和免费的,供开发者和用户共享或下载镜像。
Docker Hub:Docker 官方提供的公共镜像仓库,默认与 Docker CLI 配合使用。
Google Container Registry (GCR):Google 提供的镜像仓库(k8s1.24版本前的默认仓库),适合与 Google Cloud Platform (GCP) 集成。k8s1.24后的默认仓库:https://registry.k8s.io
GitHub Container Registry (GHCR):GitHub 提供的容器镜像服务,适合与 GitHub 项目结合使用。
Quay.io:Red Hat 提供的镜像仓库,支持高级功能和企业用途。
-
私有镜像仓库: 为了安全性和隐私原因,很多企业会搭建自己的私有镜像仓库。
Harbor:一个开源的企业级私有镜像仓库,支持镜像管理、访问控制和漏洞扫描。
Artifactory:JFrog 提供的企业级解决方案,支持多种包管理器,包括 Docker 镜像。
自建私有仓库:使用 Docker Registry 开源项目搭建的简单私有仓库。
-
云厂商提供的镜像仓库: 各大云厂商为其云服务提供了专属的容器镜像仓库,方便与云平台集成。
Amazon Elastic Container Registry (ECR):AWS 提供的镜像仓库,深度集成 AWS 生态。
Azure Container Registry (ACR):Azure 提供的镜像仓库,支持与 Azure Kubernetes 服务无缝集成。
Alibaba Cloud Container Registry (ACR):阿里云提供的镜像服务,支持国内加速访问和与阿里云服务集 成。
Tencent Container Registry (TCR):腾讯云提供的镜像仓库,适合国内用户使用。
Huawei Cloud SWR (SoftWare Repository for Container):华为云提供的容器镜像服务,支持企业级容器管理。
-
国内公共镜像加速器 由于国内网络环境的限制,许多镜像从国外仓库拉取较慢,因此国内厂商提供了一些公共镜像加速器。
阿里云容器镜像服务加速器:https://cr.console.aliyun.com
腾讯云容器镜像服务加速器:https://cloud.tencent.com/document/product/457/35996
华为云容器镜像加速器:https://www.huaweicloud.com/product/swr.html
网易云加速器:https://www.163yun.com/product/container
监控
参考:https://flashcat.cloud/blog/ops-monitor/