分类
join有如下种类
(inner) join
left (outer) join
right (outer) join
cross join :笛卡尔积,与inner join不指定on等效
straight_join :效果等同于inner join,只是指定左表为驱动表
full (outer) join :全外连接,MySQL中不支持。可用left join union right join 实现。
例如:
|
|
在MySQL中可以用下列方式实现:
|
|
驱动表与被驱动表
inner join :由驱动器决定
left join :左表为驱动表,右表为被驱动表
right join :左表为驱动表,右表为被驱动表
straight_join :固定左表为驱动表,右表为被驱动表
join执行流程
每次取驱动表一行数据,去和被驱动表匹配,即双重for循环
join执行的实现方式
Nest Loop Join(NLJ):单纯的双层循环
Block Nest Loop Join(BNLJ):在NLJ的基础上,利用Join Buffer,一次取出一批驱动表数据,可以减少循环匹配次数
Index Nest Loop Join(INLJ):在NLJ的基础上,利用被驱动表连接字段的索引直接找到匹配数据,可以减少循环次数
小表驱动大表
小表驱动大表是一种常见的SQL优化手段,其原因如下:
两表关联时会产生一个Join Buffer(关联缓存区)。Join Buffer是优化器用于处理连接查询操作时的临时缓冲区,简单来说当需要比较两个或多个表的数据进行Join操作时,JOin Buffer可以帮助MySQL临时存储结果,以减少磁盘读取和CPU负担,提高查询效率。需要注意的是每个join都有一个单独的缓冲区。
BNLJ会将驱动表数据加载到Join Buffer里,然后再批量与被驱动表进行匹配,如果驱动表数据流量较大,Join Buffer无法一次性装载驱动表的结果集,将会分阶段与被驱动表进行批量数据匹配,然后记录结果并将结果返回。如果数据量过大,Join Buffer无法一次性加载完成就会分阶段匹配,增大了磁盘读取,降低了效率
所以总结如下:
-
小表可以被完全加载到内存(Join Buffer)中: 小表的数据量相对较少,可以被完整加载到内存中,减少了磁盘IO的开销。而大表的数据量较大,可能无法完全加载到内存,需要进行磁盘IO操作,会导致性能下降。
-
减少了数据传输量: 将小表作为驱动表可以先获取小表的结果集,再根据小表的结果集进行大表的关联查询。这样可以减少传输到被驱动表的数据量,减少网络传输的开销。
-
利用索引优化(INLJ): MySQL的查询优化器通常会选择使用索引来优化关联查询。将小表作为驱动表可以更好地利用索引,因为小表的索引更容易被缓存并快速定位。
join on
on后跟连接条件,一般必须指定,且只对被驱动表有效,即使对驱动表加了过滤条件,该条件也无效。
所以,在join on之后,驱动表包含全部数据,被驱动表只包含on条件过滤后的数据。
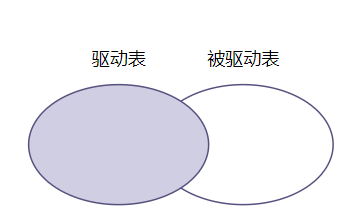
注:inner join 后的数据只会是下面两个椭圆的交集
on和where
on 在join时就会过滤数据,而where是join完成后再对数据进行过滤,所以on比where先作用。
所以,理论上过滤条件放在on后比放在where后性能更好,因为这样可以有更少的数据进入磁盘IO。
但是,由于on后的条件只对被驱动表有效,过滤条件放在on后和where后的结果可能会不一致,所以谨慎在on后加驱动表的过滤条件。
对于inner join,on和where就没有区别了
多表关联查询优化
-
加过滤条件要想清楚,先对被驱动表过滤还是join完后再一起过滤
-
尽量小表驱动大表,这是针对left join和right join的情况,inner join会由优化器自行选择
-
explain分析SQL语句得到的执行计划的第一行即是驱动表
-
优化join思路:一切为了减少join 时驱动表匹配被驱动表时的循环次数。如果join后的数据量很大,并且还要进行聚合操作,在不影响查询结果的情况下可以考虑先聚合出临时表再进行join
-
减少单表数据量,如水平分表、垂直分表
-
静态的数据可以在后端进行缓存
补充:分表设计
分表原理:一个大表按照一定的规则分解成多张具有独立存储空间的实体表。这些表可以分布在同一块磁盘上,也可以在不同的磁盘上。
通过分表实现用户在访问数据时,因不同的条件而访问不同的表,将数据分散在各个实体表中,减少单表的访问压力,提升数据查询效率
水平分表
以字段为依据,按照一定的策略,使用hash、range、list等方式将一个表的数据拆分成多个相同结构的表中。 水平分表是为了降低单表的数据量,解决单表的热点问题。
比如按时间特性进行划分,将表数据分成历年数据表或者历史数据表(已完成)+在线数据表(正在进行)。
水平分表后的表通过union能还原回原来的表。
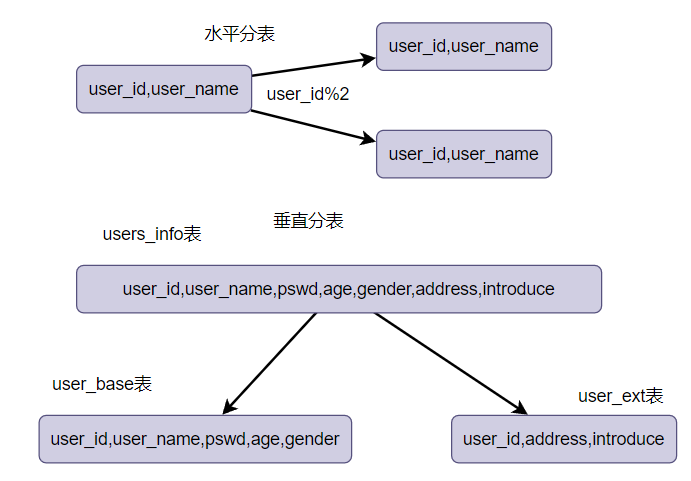
垂直分表
根据字段查询频率将表中数据拆分为不同结构的表(主表和扩展表)。
例如将热点数据和非热点数据分块存储,这样在查询热点数据时就能将数据缓存起来,减少了随机读取IO,提高了命中率。
适用于由于字段较多引起数据量和访问量较大的情况,且每个业务场景只访问部分字段。
例如:用户对商品感兴趣才会查看详细描述,而详细描述占用存储较多(Text),可以将该字段垂直分割 垂直分表后的表通过join可以还原回原来的表
垂直分表的优点:
- 不同的业务场景访问不同的内容,数据量小,提升性能
- 集成中数据传输量小
- 不同业务场景业务量访问频率不一样,表的操作更新可以更加灵活地控制
- 降低业务耦合度
- 垂直分割可使行数据变小,一个数据块就能存更多数据,在查询时可以有效减少
IO次数。垂直分表可以有效利用Cache
分区分表对比
- 定义:分区是在一张表中,根据某种规则将数据分散到不同的物理存储区域。分表则是将一张大表拆分成多张小表。
- 数据访问:在分区中,用户无需知道数据在哪个分区,可以像访问普通的表一样访问数据,但在分表中,用户必须先知道数据在哪张表中才能访问到所需数据
- 适用场景:分区适用于数据量大,但查询范围有限的场景,而分表适用于数据量大,查询范围广的场景。
- 性能:分区可以提高查询性能,因为查询只需要在一个分区内进行(过滤条件使用了分区字段),而不是在整张表中。分表可以提高整体性能,因为每个表的数据量都变少了
- 管理:分区可以减少数据的恢复。分表可以使每个表的大小更容易得到控制
广播表与分布式表
广播表:小表广播功能能提高跨库场景的性能和简化跨库场景的开发。 将需要广播的数据推送到目标库,冗余了表数据,方便在库内关联查询。
|
|
分布式表:分布式表是指其数据根据某种分片策略在分布式数据库系统的不同节点上。 数据被分成多个分段,每个分段存储在不同的节点上。 分布式表的分布策略可以基于hash、range、list等方式。 分布式表适用于数据量大且需要水平扩展的场景.
|
|
反范式
属性冗余:在一个表中除了存储关联表的主键外,将关联表的非键字段也存储到此表的处理方式。 有点像垂直分表的反向操作
|
|
级联属性冗余:多表关联时,A关联B,B关联C。在查询时需要同时获取A、B、C三个表的属性或以它们的属性进行条件过滤 ,为了减少表关联以提高性能,可以考虑在B表中冗余需要访问的C表字段,减少频繁的表关联操作。
例如:在员工表中冗余部门表的信息(部门id 部门名称 部门负责人)
表冗余:针对数据记录进行冗余,即A表的数据复制多份,或者多表关联的结果数据存储成一张表。
- 直接复制:“广播表模式”,可以提高跨库访问的性能
- 加工派生:冗余的数据是源表加工后的数据或多表关联的结果