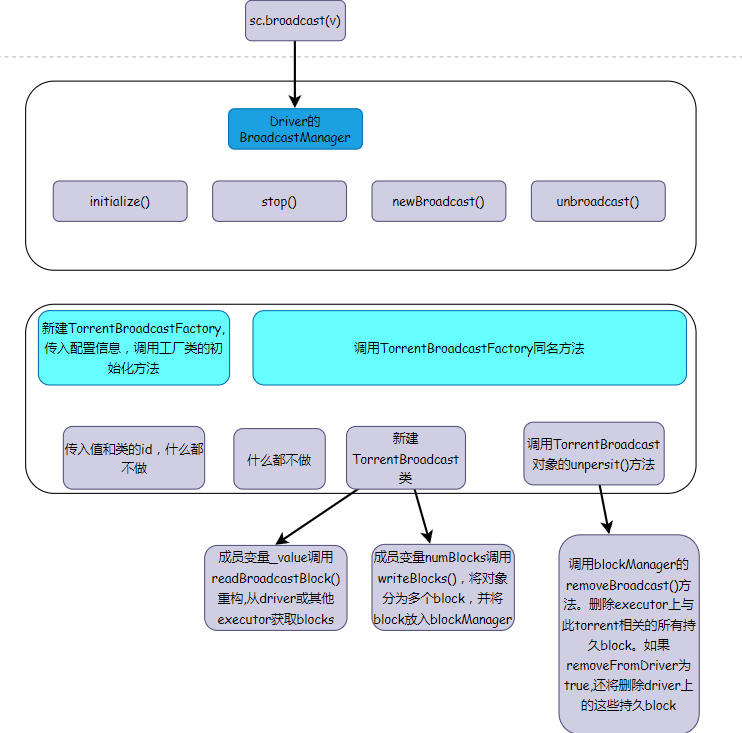
简介
广播变量允许程序员在每台机器上缓存只读变量,而不是随任务一起发送副本。 例如,它们可以用来以高效的方式为每个节点提供一个大型输入数据集的副本。 Spark 还尝试使用高效的广播算法分发广播变量,以降低通信成本。 广播变量是通过调用 broadcast 从变量 v 中创建的。 广播变量是 v 的包装器,其值可通过调用 value 方法访问。
快速上手
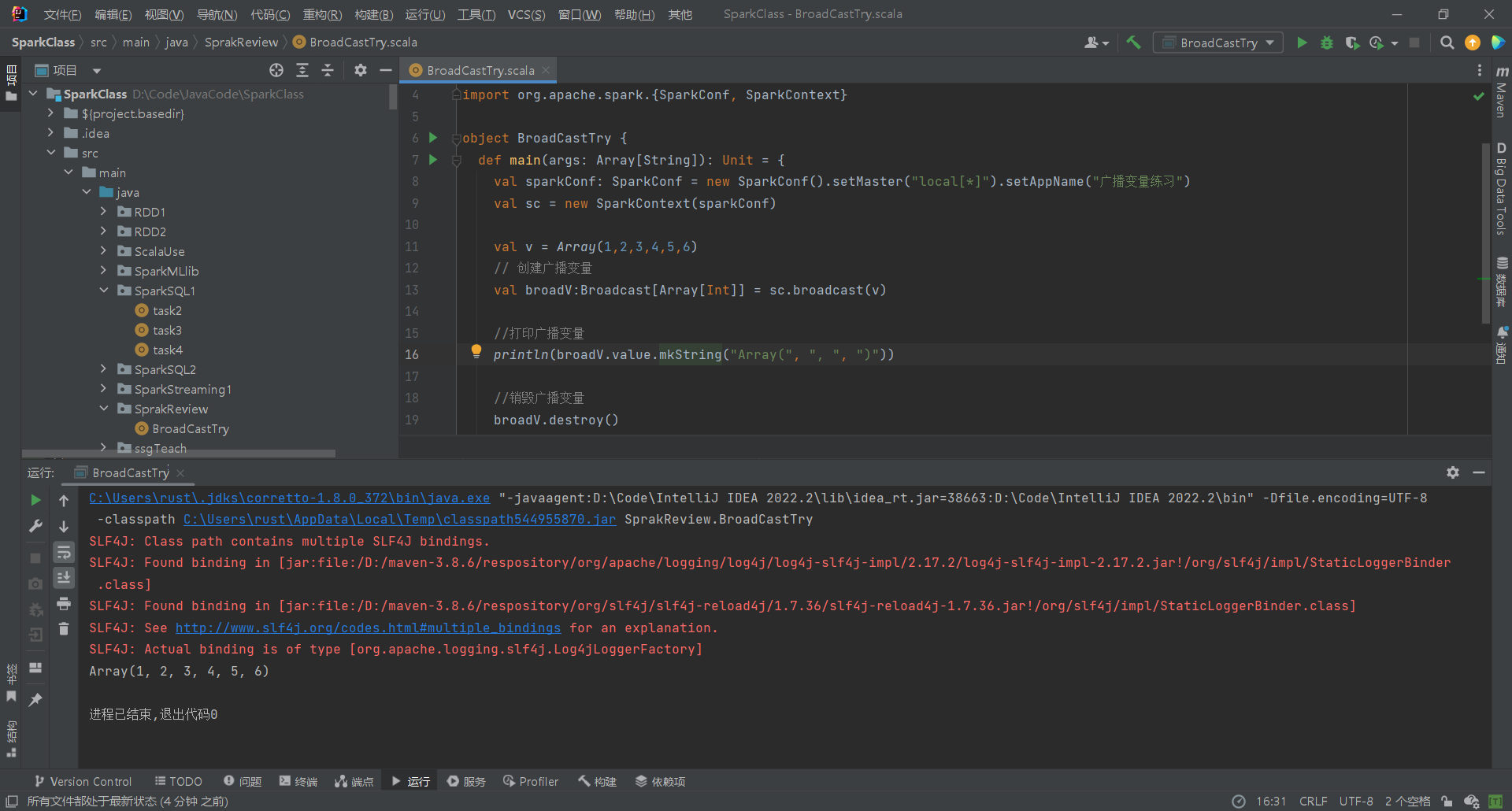
广播变量使用如简介中所说,使用sc.broadcast()包装一个变量,就创建了一个广播变量。访问广播变量的值可以通过调用其value方法,即broadV.value()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.{SparkConf, SparkContext}
object BroadCastTry {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("广播变量练习")
val sc = new SparkContext(sparkConf)
val v = Array(1,2,3,4,5,6)
// 创建广播变量
val broadV:Broadcast[Array[Int]] = sc.broadcast(v)
//打印广播变量
println(broadV.value.mkString("Array(", ", ", ")"))
//销毁广播变量
broadV.destroy()
sc.stop()
}
}
|
原理简介
参考资料:Spark Core源码精读计划11 | Spark广播机制的实现
注:本次源码阅读使用的是Spark_2.12-3.3.2(scala2.12版本写的Spark3.3.2)
简单地说,广播变量的流程如下
- 广播变量由Application的Driver使用
BroadcastManager创建,并存储在BlockManager中
- Driver将广播变量的值写到Block中,这样在driver上执行的tasks不会再创建一份新的广播变量副本
- Executor需要使用这个变量时,先从本地
BlockManager中查找有无该变量,没有的话从Driver的BlockManager远程读取该变量
- Executor获取到这个广播变量后就将它缓存到本地的
BlockManager中,避免重复地远程获取,提高性能。
使用广播变量能提高性能的原因是:
- 减少数据传输:广播变量将数据从Driver节点传输到每个Executor,只进行一次网络传输,而不是在每个任务中重复传输。
- 本地缓存:一旦Executor接收到广播变量,它会将其缓存本地,供后续任务使用,避免重复的远程获取。
- 内存效率:通过共享相同的数据副本,广播变量减少了Executor内存中的数据冗余。
这些特性一起显著减少了网络I/O和内存开销,提升了分布式计算的性能和效率。但是广播变量只能用在只读变量上,而且只适合用在比较大的变量上。
因为对于比较小的变量,直接传递给每个任务的开销很低,而且广播机制增大了任务复杂性。不能用于可变变量的原因也很明显,广播变量是由Driver创建,并由Executor远程读取。Driver或者Executor修改后都会导致计算结果错误。
补充:
BroadcastManager是位于org.apache.spark.broadcast下的类,用于创建和管理广播变量,BlockManager是位于org.apache.spark.storage下的类,用于在每个节点(Driver和Executor)上运行的管理器,为本地和远程向各种存储(内存、磁盘和堆外)放入和检索数据块提供接口。
Broadcast是位于org.apache.spark.broadcast下的抽象类,只有TorrentBroadcast一个子类,早期还有一个HttpBroadcast子类。
TorrentBroadcast是类似于 BitTorrent 的 Broadcast 实现。有同名类和对象。其机制如下: Driver将序列化对象分成小块,并将这些小块存储在Executor的 BlockManager 中。 在每个Executor上,Executor首先尝试从其 BlockManager 中获取对象。 如果对象不存在,Executor就会使用远程获取功能,从Driver和/或其他Executor(如果有的话)中获取小块对象。 获取小块后,它会将小块放入自己的 BlockManager 中,供其他执行器取用。 这样,驱动程序就不会成为发送多份广播数据(每个执行器一份)的瓶颈。 初始化时,TorrentBroadcast 对象会读取 SparkEnv.get.conf 文件。
广播管理器BroadcastManager
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
package org.apache.spark.broadcast
import java.util.Collections
import java.util.concurrent.atomic.AtomicLong
import scala.reflect.ClassTag
import org.apache.commons.collections4.map.AbstractReferenceMap.ReferenceStrength
import org.apache.commons.collections4.map.ReferenceMap
import org.apache.spark.SparkConf
import org.apache.spark.api.python.PythonBroadcast
import org.apache.spark.internal.Logging
private[spark] class BroadcastManager(
val isDriver: Boolean, conf: SparkConf) extends Logging {
private var initialized = false
private var broadcastFactory: BroadcastFactory = null
initialize()
// Called by SparkContext or Executor before using Broadcast
private def initialize(): Unit = {
synchronized {
if (!initialized) {
broadcastFactory = new TorrentBroadcastFactory
broadcastFactory.initialize(isDriver, conf)
initialized = true
}
}
}
def stop(): Unit = {
broadcastFactory.stop()
}
private val nextBroadcastId = new AtomicLong(0)
private[broadcast] val cachedValues =
Collections.synchronizedMap(
new ReferenceMap(ReferenceStrength.HARD, ReferenceStrength.WEAK)
.asInstanceOf[java.util.Map[Any, Any]]
)
def newBroadcast[T: ClassTag](value_ : T, isLocal: Boolean): Broadcast[T] = {
val bid = nextBroadcastId.getAndIncrement()
value_ match {
case pb: PythonBroadcast =>
// SPARK-28486: attach this new broadcast variable's id to the PythonBroadcast,
// so that underlying data file of PythonBroadcast could be mapped to the
// BroadcastBlockId according to this id. Please see the specific usage of the
// id in PythonBroadcast.readObject().
pb.setBroadcastId(bid)
case _ => // do nothing
}
broadcastFactory.newBroadcast[T](value_, isLocal, bid)
}
def unbroadcast(id: Long, removeFromDriver: Boolean, blocking: Boolean): Unit = {
broadcastFactory.unbroadcast(id, removeFromDriver, blocking)
}
}
|
BroadcastManager创建时传入两个参数isDriver(是否是Driver)、conf(Spark配置文件)。早期版本还有第三个变量securityManager(对应的SecurityManager),这里我只是看参考资料中的源码知道的,第三个变量具体的作用不做了解。
成员变量
BroadcastManager内有四个成员变量:
initialized表示BroadcastManager是否已经初始化完成。broadcastFactory持有广播工厂的实例(类型是BroadcastFactory特征的实现类)。nextBroadcastId表示下一个广播变量的唯一标识(AtomicLong类型的)。cachedValues用来缓存已广播出去的变量。它属于ReferenceMap类型,是apache-commons提供的一个弱引用映射数据结构。与我们常见的各种Map不同,它的键值对有可能会在GC过程中被回收。
初始化逻辑
initialize()方法做的事情也非常简单,它首先判断BroadcastManager是否已初始化。如果未初始化,就新建广播工厂TorrentBroadcastFactory,将其初始化,然后将初始化标记设为true。
1
2
3
4
5
6
7
8
9
|
private def initialize(): Unit = {
synchronized {
if (!initialized) {
broadcastFactory = new TorrentBroadcastFactory
broadcastFactory.initialize(isDriver, conf)
initialized = true
}
}
}
|
对外提供的方法
BroadcastManager提供的方法有两个:newBroadcast()方法,用于创建一个新的广播变量;以及unbroadcast()方法,将已存在的广播变量取消广播。它们都是直接调用了TorrentBroadcastFactory中的同名方法。因此我们必须通过阅读TorrentBroadcastFactory的相关源码,才能了解Spark广播机制的细节。
广播工厂类TorrentBroadcastFactory
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
package org.apache.spark.broadcast
import scala.reflect.ClassTag
import org.apache.spark.SparkConf
/**
* A [[org.apache.spark.broadcast.Broadcast]] implementation that uses a BitTorrent-like
* protocol to do a distributed transfer of the broadcasted data to the executors. Refer to
* [[org.apache.spark.broadcast.TorrentBroadcast]] for more details.
*/
private[spark] class TorrentBroadcastFactory extends BroadcastFactory {
override def initialize(isDriver: Boolean, conf: SparkConf): Unit = { }
override def newBroadcast[T: ClassTag](value_ : T, isLocal: Boolean, id: Long): Broadcast[T] = {
new TorrentBroadcast[T](value_, id)
}
override def stop(): Unit = { }
/**
* Remove all persisted state associated with the torrent broadcast with the given ID.
* @param removeFromDriver Whether to remove state from the driver.
* @param blocking Whether to block until unbroadcasted
*/
override def unbroadcast(id: Long, removeFromDriver: Boolean, blocking: Boolean): Unit = {
TorrentBroadcast.unpersist(id, removeFromDriver, blocking)
}
}
|
由源码可知,TorrentBroadcastFactory的newBroadcast()方法实际是新建了一个TorrentBroadcast类,并传入了这个类的id和值。
TorrentBroadcast类的详情参见下节。
TorrentBroadcastFactory的unbroadcast()方法传入了TorrentBroadcast类的id、
removeFromDriver(是否从驱动程序中移除状态)、blocking (是否直到未广播仍然在堵塞)。
然后删除与给定 ID 的 torrent 广播相关的所有持久化状态。这个删除持久化状态实际是SparkEnv.get.blockManager.master.removeBroadcast(id, removeFromDriver, blocking)。相关代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
def removeBroadcast(broadcastId: Long, removeFromMaster: Boolean, blocking: Boolean): Unit = {
val future = driverEndpoint.askSync[Future[Seq[Int]]](
RemoveBroadcast(broadcastId, removeFromMaster))
future.failed.foreach(e =>
logWarning(s"Failed to remove broadcast $broadcastId" +
s" with removeFromMaster = $removeFromMaster - ${e.getMessage}", e)
)(ThreadUtils.sameThread)
if (blocking) {
// the underlying Futures will timeout anyway, so it's safe to use infinite timeout here
RpcUtils.INFINITE_TIMEOUT.awaitResult(future)
}
}
|
TorrentBroadcast类
成员变量
- _value:广播块的具体数据。注意它由lazy关键字定义,因此是懒加载的,也就是在TorrentBroadcast构造时不会调用readBroadcastBlock()方法获取数据,而会推迟到第一次访问_value时。
- compressionCodec:广播块的压缩编解码逻辑。当配置项spark.broadcast.compress为true时,会启用压缩。
- blockSize:广播块的大小。由spark.broadcast.blockSize配置项来控制,默认值4MB。
- broadcastId:广播变量的ID。BroadcastBlockId是个结构非常简单的case class,每产生一个新的广播变量就会自增。
- numBlocks:该广播变量包含的块数量。它与_value不同,并没有lazy关键字定义,因此在TorrentBroadcast构造时就会直接调用writeBlocks()方法。
- checksumEnabled:是否允许对广播块计算校验值,由spark.broadcast.checksum配置项控制,默认值true。
- checksums:广播块的校验值。
writeBlocks()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
private def writeBlocks(value: T): Int = {
import StorageLevel._
// Store a copy of the broadcast variable in the driver so that tasks run on the driver
// do not create a duplicate copy of the broadcast variable's value.
val blockManager = SparkEnv.get.blockManager
if (!blockManager.putSingle(broadcastId, value, MEMORY_AND_DISK, tellMaster = false)) {
throw new SparkException(s"Failed to store $broadcastId in BlockManager")
}
try {
val blocks =
TorrentBroadcast.blockifyObject(value, blockSize, SparkEnv.get.serializer, compressionCodec)
if (checksumEnabled) {
checksums = new Array[Int](blocks.length)
}
blocks.zipWithIndex.foreach { case (block, i) =>
if (checksumEnabled) {
checksums(i) = calcChecksum(block)
}
val pieceId = BroadcastBlockId(id, "piece" + i)
val bytes = new ChunkedByteBuffer(block.duplicate())
if (!blockManager.putBytes(pieceId, bytes, MEMORY_AND_DISK_SER, tellMaster = true)) {
throw new SparkException(s"Failed to store $pieceId of $broadcastId " +
s"in local BlockManager")
}
}
blocks.length
} catch {
case t: Throwable =>
logError(s"Store broadcast $broadcastId fail, remove all pieces of the broadcast")
blockManager.removeBroadcast(id, tellMaster = true)
throw t
}
}
|
- 获取BlockManager实例,调用其putSingle()方法将广播数据作为单个对象写入本地存储。注意StorageLevel为MEMORY_AND_DISK,亦即在内存不足时会溢写到磁盘,且副本数为1,不会进行复制。
- 调用blockifyObject()方法将广播数据转化为块(block),即Spark存储的基本单元。
使用的序列化器为SparkEnv中指定的序列化器(默认Java自带的序列化,另外Spark实现了kryo序列化,可以在SparkEnv中指定)。
如果校验值开关有效,就用calcChecksum()方法为每个块计算校验值。
- 为广播数据切分成的每个块(称为piece)都生成一个带"piece"的广播ID,调用BlockManager.putBytes()方法将各个块写入MemoryStore(内存)或DiskStore(磁盘)。StorageLevel为MEMORY_AND_DISK_SER,写入的数据会序列化。
- 最终返回块的计数值。
readBroadcastBlock()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
private def readBroadcastBlock(): T = Utils.tryOrIOException {
TorrentBroadcast.torrentBroadcastLock.withLock(broadcastId) {
// As we only lock based on `broadcastId`, whenever using `broadcastCache`, we should only
// touch `broadcastId`.
val broadcastCache = SparkEnv.get.broadcastManager.cachedValues
Option(broadcastCache.get(broadcastId)).map(_.asInstanceOf[T]).getOrElse {
setConf(SparkEnv.get.conf)
val blockManager = SparkEnv.get.blockManager
blockManager.getLocalValues(broadcastId) match {
case Some(blockResult) =>
if (blockResult.data.hasNext) {
val x = blockResult.data.next().asInstanceOf[T]
releaseBlockManagerLock(broadcastId)
if (x != null) {
broadcastCache.put(broadcastId, x)
}
x
} else {
throw new SparkException(s"Failed to get locally stored broadcast data: $broadcastId")
}
case None =>
val estimatedTotalSize = Utils.bytesToString(numBlocks * blockSize)
logInfo(s"Started reading broadcast variable $id with $numBlocks pieces " +
s"(estimated total size $estimatedTotalSize)")
val startTimeNs = System.nanoTime()
val blocks = readBlocks()
logInfo(s"Reading broadcast variable $id took ${Utils.getUsedTimeNs(startTimeNs)}")
try {
val obj = TorrentBroadcast.unBlockifyObject[T](
blocks.map(_.toInputStream()), SparkEnv.get.serializer, compressionCodec)
// Store the merged copy in BlockManager so other tasks on this executor don't
// need to re-fetch it.
val storageLevel = StorageLevel.MEMORY_AND_DISK
if (!blockManager.putSingle(broadcastId, obj, storageLevel, tellMaster = false)) {
throw new SparkException(s"Failed to store $broadcastId in BlockManager")
}
if (obj != null) {
broadcastCache.put(broadcastId, obj)
}
obj
} finally {
blocks.foreach(_.dispose())
}
}
}
}
}
|
- 使用广播id对读取操作加锁,保证线程安全
- 调用
broadcastManager.cacheedValues,根据广播id检查广播变量是否已在本地缓存中,如果存在,直接返回
- 调用setConf()传入配置信息
- 尝试从本地blockManager调用
getLocalValues获取指定广播id的数据,如果有就直接读取并缓存
- 如果本地blockManager不存在,就调用
readBlocks()方法,从driver和其他executor读取指定广播id对应的piece(片)数据
- 从其他节点获取到分块数据后,将其反序列化,重建对象并存储在BlockManager中,并将重建的对象缓存
补充:readBlocks()
readBlocks()是在本地缓存和BlockManager都读取不到数据后,从其他节点读取数据的方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
private def readBlocks(): Array[BlockData] = {
// Fetch chunks of data. Note that all these chunks are stored in the BlockManager and reported
// to the driver, so other executors can pull these chunks from this executor as well.
val blocks = new Array[BlockData](numBlocks)
val bm = SparkEnv.get.blockManager
for (pid <- Random.shuffle(Seq.range(0, numBlocks))) {
val pieceId = BroadcastBlockId(id, "piece" + pid)
logDebug(s"Reading piece $pieceId of $broadcastId")
// First try getLocalBytes because there is a chance that previous attempts to fetch the
// broadcast blocks have already fetched some of the blocks. In that case, some blocks
// would be available locally (on this executor).
bm.getLocalBytes(pieceId) match {
case Some(block) =>
blocks(pid) = block
releaseBlockManagerLock(pieceId)
case None =>
bm.getRemoteBytes(pieceId) match {
case Some(b) =>
if (checksumEnabled) {
val sum = calcChecksum(b.chunks(0))
if (sum != checksums(pid)) {
throw new SparkException(s"corrupt remote block $pieceId of $broadcastId:" +
s" $sum != ${checksums(pid)}")
}
}
// We found the block from remote executors/driver's BlockManager, so put the block
// in this executor's BlockManager.
if (!bm.putBytes(pieceId, b, StorageLevel.MEMORY_AND_DISK_SER, tellMaster = true)) {
throw new SparkException(
s"Failed to store $pieceId of $broadcastId in local BlockManager")
}
blocks(pid) = new ByteBufferBlockData(b, true)
case None =>
throw new SparkException(s"Failed to get $pieceId of $broadcastId")
}
}
}
blocks
}
|
- 初始化一个
BlockData数组,长度为广播id对应piece数,获取BlockManager实例
- 通过
Random.shuffle()随机顺序遍历每个块的id,确保负载均衡
- 如果本地
BlockManager存在块id对应数据块,直接获取并存储
这里好像有点冗余,因为readBlocks()本来就是在本地缓存和BlockManager中找不到,才远程访问其他节点时调用的方法。但代码中这么写的原因已在注释中给出:
First try getLocalBytes because there is a chance that previous attempts to fetch the broadcast blocks have already fetched some of the blocks. In that case, some blocks would be available locally (on this executor).
首先尝试 getLocalBytes,因为之前获取广播数据块的尝试有可能已经获取了部分数据块。在这种情况下,一些区块将在本地(在此executor上)可用。
- 如果本地没有,调用
blockManager.getRemoteBytes(pieceId)从远程节点获取。若开启了校验和,则调用calChecksum()计算校验和并比较,来验证数据完整性
- 将从远端获取的数据块存储到本地
BlcokManager中。
获取远端数据封装了很多层,大体读取顺序如下图
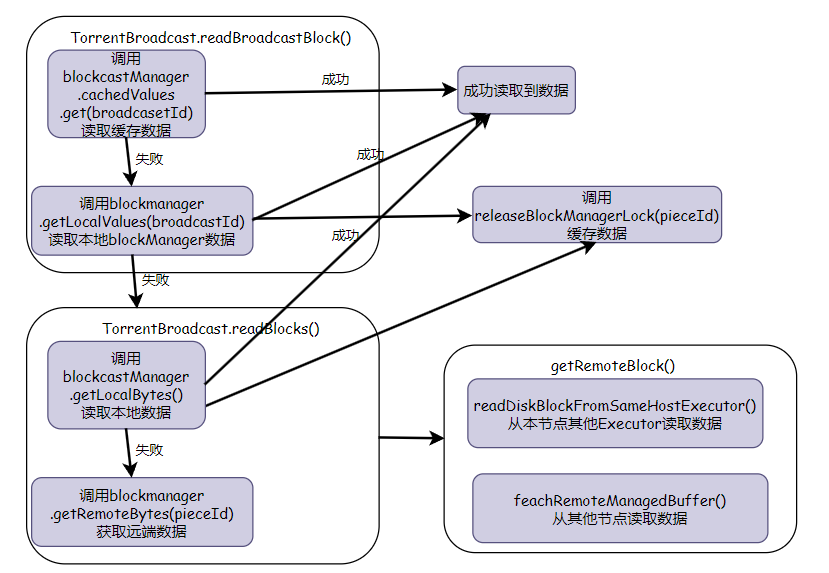 获取远端数据的最后一步,从其他节点读取数据属于BlockManager的部分,下次有机会再读一读
获取远端数据的最后一步,从其他节点读取数据属于BlockManager的部分,下次有机会再读一读
总结
广播变量的底层机制总结如下图: