简介
累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在
Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,
传回 Driver 端进行 merge。
快速上手
数据如下,数据格式为学生姓名,学生课程,课程成绩。要求计算选择了Database课程的人数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package SprakReview
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
object AccumulatorTry {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("累加器学习")
val sc = new SparkContext(sparkConf)
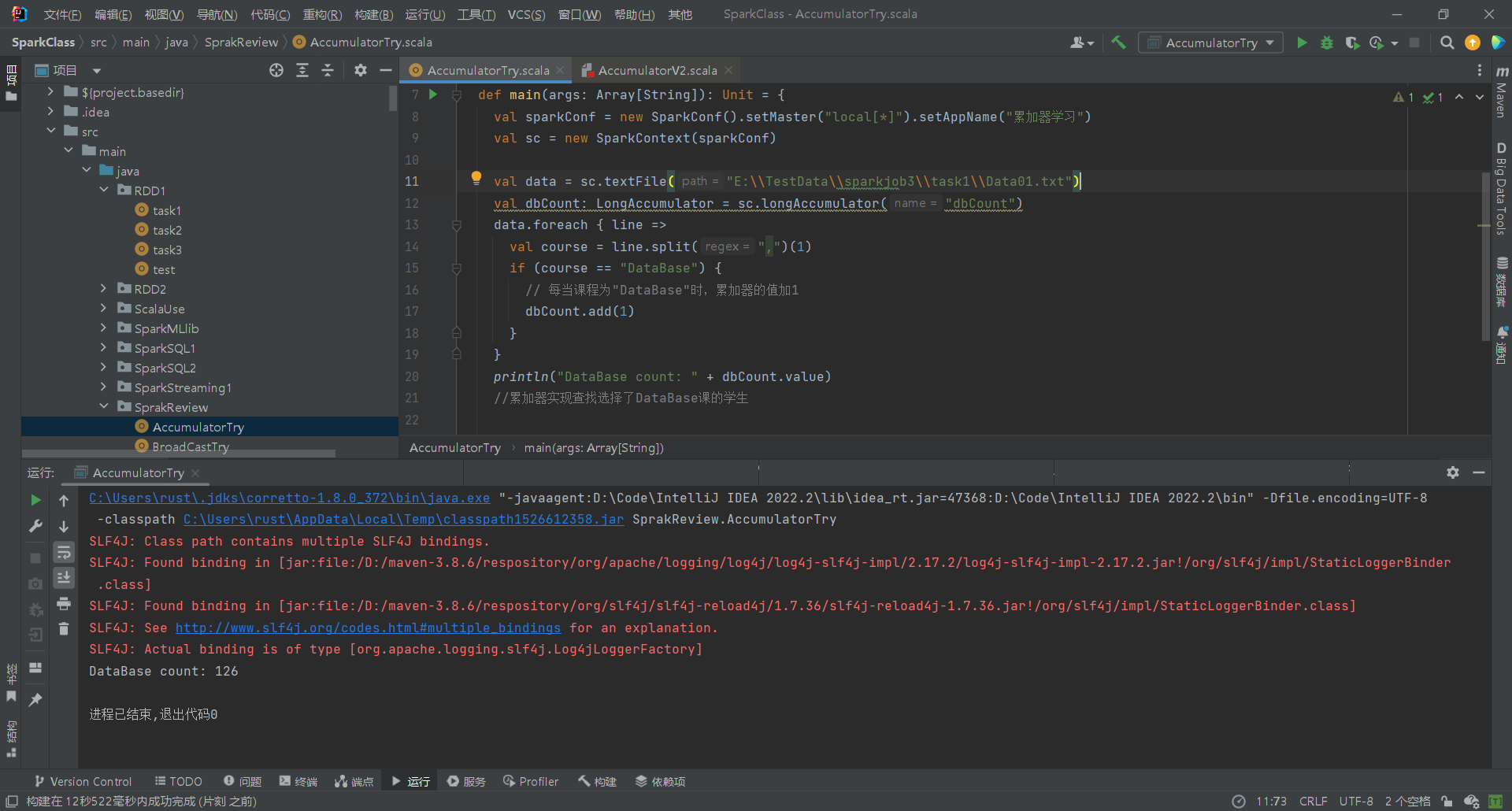
val data = sc.textFile("E:\\TestData\\sparkjob3\\task1\\Data01.txt")
val dbCount: LongAccumulator = sc.longAccumulator("dbCount")
data.foreach { line =>
val course = line.split(",")(1)
if (course == "DataBase") {
// 每当课程为"DataBase"时,累加器的值加1
dbCount.add(1)
}
}
println("DataBase count: " + dbCount.value)
//累加器实现查找选择了DataBase课的学生
sc.stop()
}
}
|
原理简介
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
/**
* Create and register a long accumulator, which starts with 0 and accumulates inputs by `add`.
*/
def longAccumulator: LongAccumulator = {
val acc = new LongAccumulator
register(acc)
acc
}
/**
* Create and register a long accumulator, which starts with 0 and accumulates inputs by `add`.
*/
def longAccumulator(name: String): LongAccumulator = {
val acc = new LongAccumulator
register(acc, name)
acc
}
/**
* Create and register a double accumulator, which starts with 0 and accumulates inputs by `add`.
*/
def doubleAccumulator: DoubleAccumulator = {
val acc = new DoubleAccumulator
register(acc)
acc
}
/**
* Create and register a double accumulator, which starts with 0 and accumulates inputs by `add`.
*/
def doubleAccumulator(name: String): DoubleAccumulator = {
val acc = new DoubleAccumulator
register(acc, name)
acc
}
/**
* Create and register a `CollectionAccumulator`, which starts with empty list and accumulates
* inputs by adding them into the list.
*/
def collectionAccumulator[T]: CollectionAccumulator[T] = {
val acc = new CollectionAccumulator[T]
register(acc)
acc
}
/**
* Create and register a `CollectionAccumulator`, which starts with empty list and accumulates
* inputs by adding them into the list.
*/
def collectionAccumulator[T](name: String): CollectionAccumulator[T] = {
val acc = new CollectionAccumulator[T]
register(acc, name)
acc
}
|
Spark中的累加器有三种doubleAccumulator、longAccumulator、collectionAccumulator。分别有传入累加器名字和不穿名字的函数。
累加器会新建一个对应的累加器类,然后在driver注册,传不传名字的区别是注册的时候会不会传入名字,最后返回已注册的累加器。
源码中对注册的解释如下:
Registers an AccumulatorV2 created on the driver such that it can be used on the executors.
All accumulators registered here can later be used as a container for accumulating partial values across multiple tasks. This is what org.apache.spark.scheduler.DAGScheduler does. Note: if an accumulator is registered here, it should also be registered with the active context cleaner for cleanup so as to avoid memory leaks.
If an AccumulatorV2 with the same ID was already registered, this does nothing instead of overwriting it. We will never register same accumulator twice, this is just a sanity check.
注册在driver上创建的 AccumulatorV2,以便在executor上使用。 在此注册的所有累加器以后都可用作容器,用于累加多个任务中的部分值。 这就是 org.apache.spark.scheduler.DAGScheduler 的作用。 注意:如果在这里注册了累加器,那么它也应注册到活动上下文清理器中进行清理,以避免内存泄漏。 如果已经注册了具有相同 ID 的 AccumulatorV2,则不会做任何操作,而会覆盖它。 我们永远不会注册同一个累加器两次,这只是为了进行合理性检查。
累加器类
LongAccumulator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
/**
* An [[AccumulatorV2 accumulator]] for computing sum, count, and average of 64-bit integers.
*
* @since 2.0.0
*/
class LongAccumulator extends AccumulatorV2[jl.Long, jl.Long] {
private var _sum = 0L
private var _count = 0L
/**
* Returns false if this accumulator has had any values added to it or the sum is non-zero.
*
* @since 2.0.0
*/
override def isZero: Boolean = _sum == 0L && _count == 0
override def copy(): LongAccumulator = {
val newAcc = new LongAccumulator
newAcc._count = this._count
newAcc._sum = this._sum
newAcc
}
override def reset(): Unit = {
_sum = 0L
_count = 0L
}
/**
* Adds v to the accumulator, i.e. increment sum by v and count by 1.
* @since 2.0.0
*/
override def add(v: jl.Long): Unit = {
_sum += v
_count += 1
}
/**
* Adds v to the accumulator, i.e. increment sum by v and count by 1.
* @since 2.0.0
*/
def add(v: Long): Unit = {
_sum += v
_count += 1
}
/**
* Returns the number of elements added to the accumulator.
* @since 2.0.0
*/
def count: Long = _count
/**
* Returns the sum of elements added to the accumulator.
* @since 2.0.0
*/
def sum: Long = _sum
/**
* Returns the average of elements added to the accumulator.
* @since 2.0.0
*/
def avg: Double = _sum.toDouble / _count
override def merge(other: AccumulatorV2[jl.Long, jl.Long]): Unit = other match {
case o: LongAccumulator =>
_sum += o.sum
_count += o.count
case _ =>
throw new UnsupportedOperationException(
s"Cannot merge ${this.getClass.getName} with ${other.getClass.getName}")
}
private[spark] def setValue(newValue: Long): Unit = _sum = newValue
override def value: jl.Long = _sum
}
|
LongAccumulator类是一个自定义累加器,用于计算64位整数的总和、计数和平均值。它继承自AccumulatorV2。
私有变量_sum:(存储累加的总和)、_count(存储累加的元素个数)。
用于计算整型数据的总和、计数和平均值,并在driver中访问结果。
isZero方法:检查累加器是否未添加任何值或总和为零。
copy方法:创建累加器的副本,包括当前的_sum和_count。
reset方法:将_sum和_count重置为零。
add方法:增加一个值到累加器中,更新_sum和_count。有两个重载版本,接收jl.Long和Long类型。
(jl.Long是java.lang.Long的缩写。是Java的类类型,用于包装一个long的值。
提供了许多方法来处理long类型的数据,比如转换、比较等。用于与Java类进行交互时的包装器类型。
Long是Scala的基本数据类型。直接表示一个64位的整数。)
count方法:返回添加到累加器中的元素个数。
sum方法:返回累加器中的元素总和。
avg方法:返回累加器中元素的平均值。
merge方法:将另一个LongAccumulator的值合并到当前累加器。如果尝试与非LongAccumulator类型合并,会抛出异常。
setValue方法:设置累加器的总和值(仅用于内部)。
value方法:返回累加器的当前总和。
DoubleAccumulator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
/**
* An [[AccumulatorV2 accumulator]] for computing sum, count, and averages for double precision
* floating numbers.
*
* @since 2.0.0
*/
class DoubleAccumulator extends AccumulatorV2[jl.Double, jl.Double] {
private var _sum = 0.0
private var _count = 0L
/**
* Returns false if this accumulator has had any values added to it or the sum is non-zero.
*/
override def isZero: Boolean = _sum == 0.0 && _count == 0
override def copy(): DoubleAccumulator = {
val newAcc = new DoubleAccumulator
newAcc._count = this._count
newAcc._sum = this._sum
newAcc
}
override def reset(): Unit = {
_sum = 0.0
_count = 0L
}
/**
* Adds v to the accumulator, i.e. increment sum by v and count by 1.
* @since 2.0.0
*/
override def add(v: jl.Double): Unit = {
_sum += v
_count += 1
}
/**
* Adds v to the accumulator, i.e. increment sum by v and count by 1.
* @since 2.0.0
*/
def add(v: Double): Unit = {
_sum += v
_count += 1
}
/**
* Returns the number of elements added to the accumulator.
* @since 2.0.0
*/
def count: Long = _count
/**
* Returns the sum of elements added to the accumulator.
* @since 2.0.0
*/
def sum: Double = _sum
/**
* Returns the average of elements added to the accumulator.
* @since 2.0.0
*/
def avg: Double = _sum / _count
override def merge(other: AccumulatorV2[jl.Double, jl.Double]): Unit = other match {
case o: DoubleAccumulator =>
_sum += o.sum
_count += o.count
case _ =>
throw new UnsupportedOperationException(
s"Cannot merge ${this.getClass.getName} with ${other.getClass.getName}")
}
private[spark] def setValue(newValue: Double): Unit = _sum = newValue
override def value: jl.Double = _sum
}
|
DoubleAccumulator与LongAccumulator区别不大,主要区别在DoubleAccumulator的_sum为Double类型。
CollectionAccumulator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
/**
* An [[AccumulatorV2 accumulator]] for collecting a list of elements.
*
* @since 2.0.0
*/
class CollectionAccumulator[T] extends AccumulatorV2[T, java.util.List[T]] {
private var _list: java.util.List[T] = _
private def getOrCreate = {
_list = Option(_list).getOrElse(new java.util.ArrayList[T]())
_list
}
/**
* Returns false if this accumulator instance has any values in it.
*/
override def isZero: Boolean = this.synchronized(getOrCreate.isEmpty)
override def copyAndReset(): CollectionAccumulator[T] = new CollectionAccumulator
override def copy(): CollectionAccumulator[T] = {
val newAcc = new CollectionAccumulator[T]
this.synchronized {
newAcc.getOrCreate.addAll(getOrCreate)
}
newAcc
}
override def reset(): Unit = this.synchronized {
_list = null
}
override def add(v: T): Unit = this.synchronized(getOrCreate.add(v))
override def merge(other: AccumulatorV2[T, java.util.List[T]]): Unit = other match {
case o: CollectionAccumulator[T] => this.synchronized(getOrCreate.addAll(o.value))
case _ => throw new UnsupportedOperationException(
s"Cannot merge ${this.getClass.getName} with ${other.getClass.getName}")
}
override def value: java.util.List[T] = this.synchronized {
java.util.Collections.unmodifiableList(new ArrayList[T](getOrCreate))
}
private[spark] def setValue(newValue: java.util.List[T]): Unit = this.synchronized {
_list = null
getOrCreate.addAll(newValue)
}
}
|
CollectionAccumulator类是一个用于收集元素列表的自定义累加器。它继承自AccumulatorV2(在Spark中创建累加器的基类,自定义累加器也需要继承这个类)。具有私有变量 _list,用于存储累积的元素列表,初始为null。使用synchronized确保了对_list的操作是线程安全的。主要用途是在任务中收集元素并在driver上提供收集到的数据。 _list类型是java.util.List,所以java.util.List的方法都可以在这里正常使用(setValue就是先情况_list,再调用List的addAll添加一个java.util.List)。
getOrCreate方法:确保_list已初始化,如果为null,则创建一个新的ArrayList(java.util.ArrayList)。
isZero方法:检查累加器是否为空,如果为空则返回true。
copyAndReset方法:创建一个没有累积值的新CollectionAccumulator。
copy方法:创建一个新的CollectionAccumulator并复制当前元素。
reset方法:通过将_list设置为null来清空累加器。
add方法:向累加器中添加一个元素。
merge方法:将另一个累加器的值合并到这个累加器中,仅支持与另一个CollectionAccumulator合并。
value方法:返回累积列表的不可修改视图。
setValue方法:重置累加器并设置为新的元素列表。