学习源码所用的Spark的版本是Spark3.3.2_2.12(Scala2.12写的Spark3.3.2)
类别
Spark底层有五种join实现方式
前置介绍:HashJoin
参考资料:https://www.6aiq.com/article/1533984288407
先来看看这样一条SQL语句:select * from order,item where item.id = order.i_id,很简单一个Join节点,参与join的两张表是item和order,join key分别是item.id以及order.i_id。现在假设这个Join采用的是hash join算法,整个过程会经历三步:
-
确定Build Table以及Probe Table:这个概念比较重要,Build Table使用join key构建Hash Table,而Probe Table使用join key进行探测,探测成功就可以join在一起。通常情况下,小表会作为Build Table,大表作为Probe Table。此事例中item为Build Table,order为Probe Table。
-
构建Hash Table:依次读取Build Table(item)的数据,对于每一行数据根据join key(item.id)进行hash,hash到对应的Bucket,生成hash table中的一条记录。数据缓存在内存中,如果内存放不下需要dump到外存。
-
探测:再依次扫描Probe Table(order)的数据,使用相同的hash函数映射Hash Table中的记录,映射成功之后再检查join条件(item.id = order.i_id),如果匹配成功就可以将两者join在一起。
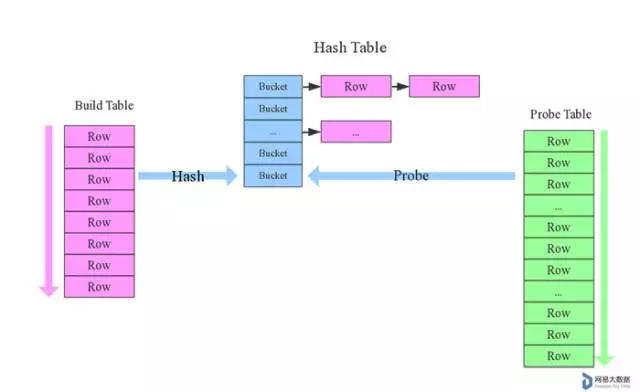
基本流程可以参考上图,这里有两个小问题需要关注:
- hash join性能如何?
很显然,hash join基本都只扫描两表一次,可以认为o(a+b),较之最极端的笛卡尔集运算a*b,效率大大提升。
- 为什么Build Table选择小表?
道理很简单,因为构建的Hash Table最好能全部加载在内存,效率最高;这也决定了hash join算法只适合至少一个小表的join场景,对于两个大表的join场景并不适用。
hash join是传统数据库中的单机join算法,在分布式环境下需要经过一定的分布式改造,就是尽可能利用分布式计算资源进行并行化计算,提高总体效率。hash join分布式改造一般有两种经典方案:
- broadcast hash join:
将其中一张小表广播分发到另一张大表所在的分区节点上,分别并发地与其上的分区记录进行hash join。broadcast适用于小表很小,可以直接广播的场景。
- shuffled hash join:
一旦小表数据量较大,此时就不再适合进行广播分发。这种情况下,可以根据join key相同必然分区相同的原理,将两张表分别按照join key进行重新组织分区,这样就可以将join分而治之,划分为很多小join,充分利用集群资源并行化。
下面分别进行详细讲解。
BroadcastHashJoinExec
- broadcast阶段:
将小表广播分发到大表所在的所有主机。广播算法可以有很多,最简单的是先发给driver,driver再统一分发给所有executor;要不就是基于BitTorrent的TorrentBroadcast。
- hash join阶段:
在每个executor上执行单机版hash join,小表映射,大表试探。
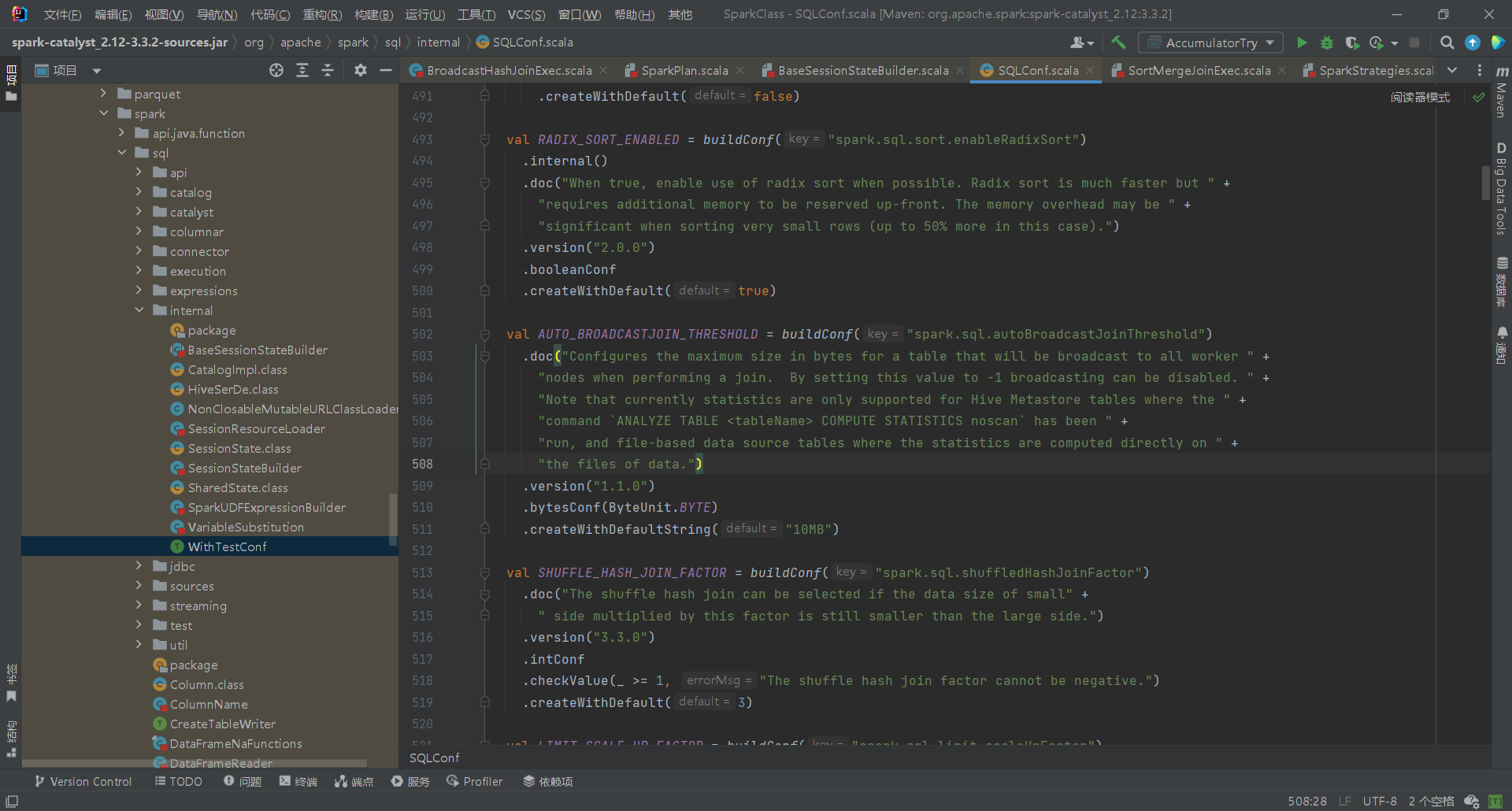
SparkSQL规定broadcast hash join执行的基本条件为被广播小表必须小于参数spark.sql.autoBroadcastJoinThreshold,默认为10M。
源码位于org.apache.spark.sql.internal.SQLConf.scala,没找到SQLConf文件可以在BaseSessionStateBuilder里找到conf引用,然后CTRL+左键查看源码。
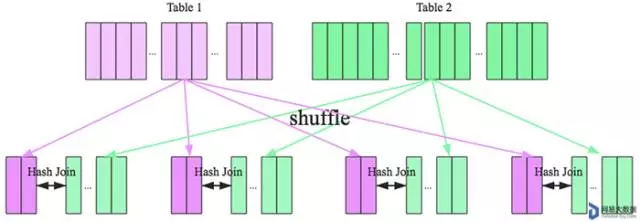
ShuffledHashJoinExec
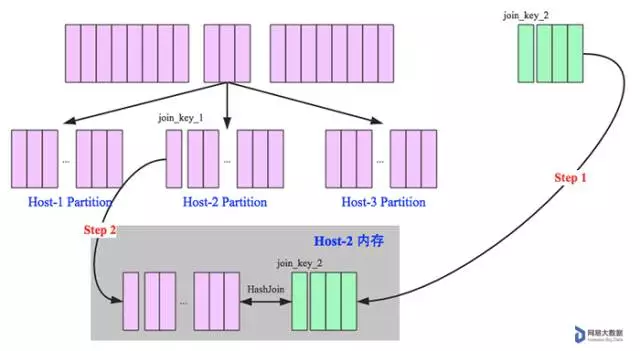
在大数据条件下如果一张表很小,执行join操作最优的选择无疑是broadcast hash join,效率最高。但是一旦小表数据量增大,广播所需内存、带宽等资源必然就会太大,broadcast hash join就不再是最优方案。此时可以按照join key进行分区,根据key相同必然分区相同的原理,就可以将大表join分而治之,划分为很多小表的join,充分利用集群资源并行化。如下图所示,shuffle hash join也可以分为两步:
- shuffle阶段:
分别将两个表按照join key进行分区,将相同join key的记录重分布到同一节点,两张表的数据会被重分布到集群中所有节点。这个过程称为shuffle。
- hash join阶段:
每个分区节点上的数据单独执行单机hash join算法。
SortMergeJoinExec
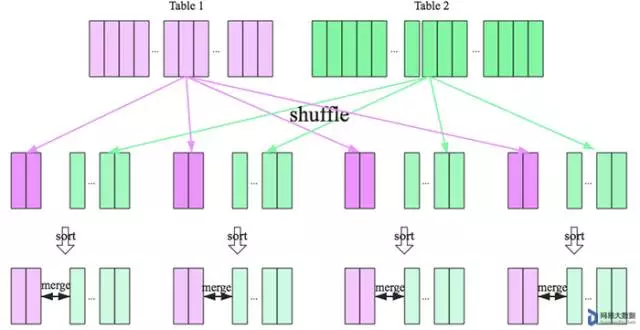
SparkSQL对两张大表join采用了全新的算法——sort merge join,整个过程分为三个步骤:
- shuffle阶段:
将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理。
- sort阶段:
对单个分区节点的两表数据,分别进行排序。
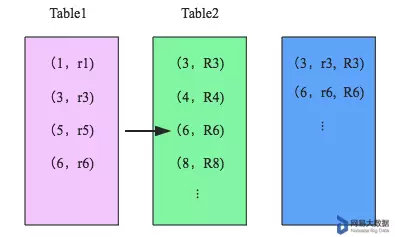
- merge阶段:
对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边。如下图所示:
CartesianProductExec:
- 初始化:两个数据集被加载并分区。
- 分区组合:每个分区的所有元素与另一个分区的所有元素组合。这在逻辑上类似于嵌套循环。
- 生成所有组合:对每一对元素生成一个元组,形成笛卡尔积。结果集的大小为两个数据集大小的乘积。
笛卡尔积会占用大量内存,使用笛卡尔积之前最好先过滤掉无用数据,其中一张表为极小表时建议广播。
BroadcastNestedLoopJoinExec
- broadcast阶段:将小表的数据复制并广播到大表分区数据所在的每个执行节点。
- 嵌套循环连接:
- 在每个执行节点上,对于分区中的每一行,逐行扫描广播的小表。
- 对每一对行执行连接条件,生成匹配的结果。
- 生成结果:将匹配的行组合成结果集。结果在每个节点独立生成,最后输出为完整的连接结果。
另外,Spark对非等值连接的支持只有这种和笛卡尔积(CartesianProduct)。 如果两张表都很大且无法广播,Spark 可能需要通过优化或变通的方法来处理:
- 数据过滤:在连接前尽量过滤数据,减少处理的数据量。
- 分区和缓存:有效地分区和缓存数据以提高性能。
- 自定义 UDF:在某些情况下,使用自定义 UDF 可能会帮助实现复杂的连接逻辑。
选择join的机制
相关源码位于
org.apache.spark.sql.execution下的141行JoinSelection对象
根据连接策略提示、等价连接键的可用性和连接关系的大小,选择合适的连接物理计划。 以下是现有的连接策略、其特点和局限性。
- broadcast hash join(BHJ): 仅支持等价连接,而连接键无需可排序。 支持除全外部连接外的所有连接类型。 当广播方较小时,BHJ 通常比其他连接算法执行得更快。 不过,广播表是一种网络密集型操作,在某些情况下可能会导致 OOM 或性能不佳,尤其是当构建/广播方较大时。
- shuffled hash join: 仅支持等价连接,而连接键无需可排序。 支持所有连接类型。 从表中构建哈希映射是一个内存密集型操作,当联编侧很大时可能会导致 OOM。
- shuffle sort merge join(SMJ): 仅支持等连接,且连接键必须是可排序的。 支持所有连接类型。
- Broadcast nested loop join(广播嵌套循环连接 BNLJ): 支持等连接和非等连接。 支持所有连接类型,但优化了以下方面的实现: 1)在右外连接中广播左侧;2)在左外、左半、左反或存在连接中广播右侧;3)在类内连接中广播任一侧。 对于其他情况,我们需要多次扫描数据,这可能会相当慢。
- Shuffle-and-replicate nested loop join (洗牌复制嵌套循环连接,又称笛卡尔积连接): 支持等连接和非等连接。 只支持内同类连接。
源码中关于等值连接选择join的机制介绍如下:
|
|
翻译如下:
如果是等值连接,我们首先按以下顺序查看连接提示(join hints):
- broadcast hint:如果支持广播散列连接(BHJ),则选择广播散列连接。 如果双方有广播提示,则选择较小的一方(根据统计信息)进行广播。
- sort merge hint:如果连接键可排序,则选择排序合并连接。
- shuffle hash hint:如果支持连接类型,我们会选择洗牌散列连接。 如果双方都有洗牌散列提示,则选择较小的一方(基于统计信息)作为构建方。 构建侧。
- shuffle replicate NL 提示:如果连接类型是内连接,则选择笛卡尔积。
如果没有提示或提示不适用,我们将逐一遵循这些规则:
- 如果有一方足够小,可以广播,且连接类型支持,则选择广播散列连接。 支持。 如果两边都很小,则选择较小的一边(根据统计数据) 进行广播。
- 如果一方的规模小到足以建立本地哈希映射,并且比另一方小很多,并且支持 “space”,则选择 “洗牌哈希连接”。
且
spark.sql.join.preferSortMergeJoin为 false。 - 如果连接键可排序,则选择排序合并连接。
- 如果连接类型为inner join(就是不明写join的join,即类似
select * from order,item),则选择笛卡尔积。 - 选择广播嵌套循环连接作为最终解决方案。 可能会出现 OOM,但我们没有 其他选择。
相关关键源码如下:
|
|
综上所述:
- 有连接提示时,优先级从高到低:BroadcastHashJoin > SortMergeJoin > ShuffledHashJoin > CartesianProduct
- 没有连接提示时,优先级从高到低(join代价从小到大):BroadcastHashJoin > ShuffledHashJoin > SortMergeJoin > CartesianProduct > BroadcastNestedLoopJoin
注意:有提示时优先SortMergeJoin,然后ShuffledHashJoin;而没有提示时,优先ShuffledHashJoin,然后SortMergeJoin。
总结: 数据仓库设计时最好避免大表与大表的join查询,SparkSQL也可以根据内存资源、带宽资源适量将参数spark.sql.autoBroadcastJoinThreshold调大,让更多join实际执行为broadcast hash join。
- 大表join极小表(表大小小于10M,可调整
spark.sql.autoBroadcastJoinThreshold参数进行修改),用BroadcastHashJoin - 大表join小表,用ShuffledHashJoin
- 大表join大表,用SortMergeJoin
非等值连接仅CartesianProduct 和 BroadcastNestedLoopJoin支持,常用BroadcastNestedLoopJoin。
补充:RDD中的join
前文中介绍的join都是SparkSQL中join的底层实现,但是在Spark的RDD中,也有一个join函数。 具体实现如下:
|
|
RDD的join实际是匹配两个RDD,以join为例,遍历(iterator)两个RDD的分区,调用cogroup函数将两个RDD的相同分区联合成一个turple返回。