作者由于水平问题,文中也许有一些错误遗漏的地方,欢迎联系指正(
2024087171@qq.com)
简介
参考资料:https://blog.csdn.net/weixin_42868529/article/details/84622803
Shuffle 过程本质上都是将 Map 端获得的数据使用分区器进行划分,并将数据发送给对应的 Reducer 的过程。
前一个stage的ShuffleMapTask进行shuffle write,把数据存储在blockManager上面,并且把数据元信息上报到dirver的mapOutTarck组件中,下一个stage根据数据位置源信息,进行shuffle read,拉取上一个stage的输出数据
Hadoop(MapReduce) shuffle
参考资料:尚硅谷Hadoop相关课程
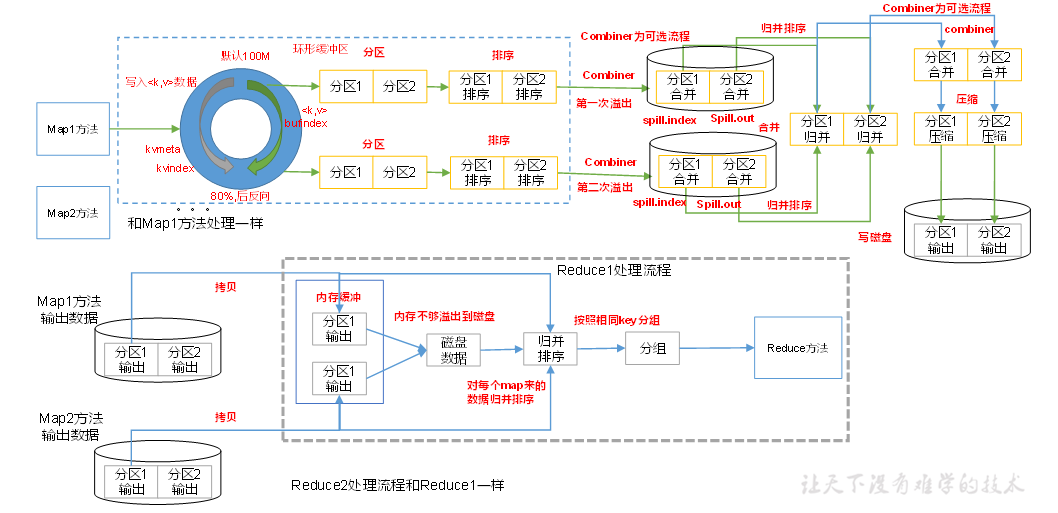
MapReduce的shuffle机制:
- MapTask收集我们的map()方法输出的kv对,放到环形缓冲区中
- 从环形缓冲区不断溢写本地磁盘文件,可能会溢出多个文件
- 多个溢出文件会被合并成大的溢出文件
- 在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
- ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
- ReduceTask会抓取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
- 合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
Spark shuffle详细机制
Spark的shuffle机制:
前提条件:Spark的代码在运行到action算子时触发任务(job),然后DAGscheduler按算子间的血缘(依赖关系)划分形成DAG图(有向无环图), 有shuffle操作的依赖关系称为宽依赖,没有的称为窄依赖。DAGscheduler按宽依赖将任务划分为多个stage,stage的数量就等于宽依赖数量+1。
- 根据 spark.shuffle.manager 设置,SparkEnv 会在driver和每个executor上创建一个 ShuffleManager。 driver在其中注册shuffle,executor(或在driver中本地运行的任务)可以要求读写数据。
- 前一个stage的ShuffleMapTask将mapTaskID和partitions传入sortShuffleManager,调用getWriter()方法后,首先会判断是否需要对计算结果进行聚合,然后将最终结果按照不同的 reduce 端进行区分,返回writeHandle,
根据不同的writeHandle选择不同的writer(
UnsafeShuffleWriter、BypassMergeSortShuffleWriter、SortShuffleWriter) - writer将数据写入到executor的blockManager中
- shuffleManager为后一个stage创建一个
BlockStoreShuffleReader,根据位置信息(startMapIndex, endMapIndex, startPartition, endPartition)拉取blockManger中的数据,根据数据的 Key 进行聚合,然后判断是否需要排序,最后生成新的 RDD。
|
|
与Hadoop(MapReduce) shuffle的区别
参考:https://zhuanlan.zhihu.com/p/136466667
- 功能上,MR的shuffle和Spark的shuffle是没啥区别的,都是对Map端的数据进行分区,要么聚合排序,要么不聚合排序,然后Reduce端或者下一个调度阶段进行拉取数据,完成map端到reduce端的数据传输功能。
- 方案上,有很大的区别,MR的shuffle是基于合并排序的思想,在数据进入reduce端之前,都会进行sort,为了方便后续的reduce端的全局排序,而Spark的shuffle是可选择的聚合,特别是1.2之后,需要通过调用特定的算子才会触发排序聚合的功能。
- 流程上,MR的Map端和Reduce区分非常明显,两块涉及到操作也是各司其职,而Spark的RDD是内存级的数据转换,不落盘,所以没有明确的划分,只是区分不同的调度阶段,不同的算子模型。
- 数据拉取,MR的reduce是直接拉取Map端的分区数据,而Spark是根据MapId和TaskContext读取,而且是在action触发的时候才会拉取数据。
ShuffleWriter及其选择策略
UnsafeShuffleWriter
|
|
当shuffle后的分区数小于等于sortShuffleManager的最大分区数时,进行unsafeShuffle。主要步骤:
- 将内存中的对象通过Java可迭代对象转换器转换为Scala的可迭代对象(并没有进行序列化相关操作,只是为了兼容性)
- 判断排序器(
sorter)是否为空,使用分区器(partitioner)确认记录所属分区 - 重置序列化缓冲区,遍历可迭代对象(
iterator),将记录的键和值依次序列化后写入,并刷写脏页,确保数据写入缓冲区 - 将序列化记录插入到排序器中。sorter负责按分区组织记录,并可能在每个分区内对其进行排序。方法使用缓冲区、偏移量、大小和分区ID来正确放置记录。
sorter什么时候排序?
- Shuffle操作的需求(最高优先级): 如果上层的Spark操作(如sortByKey)要求数据在每个分区内有序,那么排序器会对数据进行排序。 对于不需要排序的操作(如groupByKey),排序器可能只负责将数据按分区组织,而不进行排序。
- 排序器的类型和实现: Spark中有多种排序器实现,例如UnsafeExternalSorter。这些排序器可以根据需要对数据进行排序。 如果排序器的实现支持排序,并且配置要求排序,那么数据会在每个分区内被排序。
- 配置和优化(最低优先级): Spark的某些配置参数可以影响排序行为。例如,spark.shuffle.sort.bypassMergeThreshold可以决定在某些情况下是否绕过排序。 在某些优化场景下,为了提高性能,Spark可能会选择不进行排序。
BypassMergeSortShuffleWriter
|
|
BypassMergeSortShuffleWriter,专门用于处理小规模的 shuffle 操作。它通过绕过排序步骤来提高性能,适用于分区数较少的情况。
- 初始化和检查:确保在写入开始时,partitionWriters 为空,防止重复初始化,然后创建一个用于写入 shuffle 输出的对象(
ShuffleMapOutputWriter)。 - 处理空记录集:如果没有记录需要写入,更新 map 状态,直接向blockkManager提交所有分区并返回。
- 初始化序列化和写入器:创建一个新的序列化实例,初始化分区磁盘写入器数组(
DiskBlockObjectWriter[numPartitions]),初始化分区文件段数组。 - 创建分区写入器:循环遍历每个分区,创建临时的 shuffle 块和对应的磁盘写入器。为每个分区创建一个磁盘写入器。
- 写入记录: 遍历所有记录,根据键的分区,将记录写入对应的分区写入器。
- 提交和获取分区数据:遍历每个分区,提交写入的数据并获取文件段。提交写入并获取文件段信息。
- 写入分区数据和更新状态: 将分区数据写入输出。更新 map 状态。
文件段信息通常指的是每个分区在磁盘上的物理存储信息,包括:文件路径(数据在磁盘上的具体存储位置)、偏移量(数据在文件中的起始位置)、 长度(数据的字节长度)。
更新 map 状态是指在 shuffle 写入完成后,更新 Spark 的内部状态以反映当前任务的输出状态。具体来说:
- MapStatus: 这是 Spark 用于跟踪每个 map 任务输出状态的对象(在一个 stage 中,map 任务完成后生成的输出信息。这些信息用于指导后续的 shuffle 操作,确保数据能够正确地传递到下一个 stage 的 reduce 任务中。)。它包含了每个分区的数据长度信息。
源码中介绍如下:
Result returned by a ShuffleMapTask to a scheduler. Includes the block manager address that the task has shuffle files stored on as well as the sizes of outputs for each reducer, for passing on to the reduce tasks.
ShuffleMapTask 返回给调度程序的结果。 包括该任务存储了 Shuffle 文件的blockManager地址,以及给每个reducer的输出文件大小,以便传递给reduce。
- blockManager.shuffleServerId(): 这是当前节点的标识符,用于标识数据存储的位置。
- partitionLengths: 这是一个数组,包含了每个分区的数据长度。 更新 map 状态的目的是为了让 Spark 的调度器和后续的 reduce 任务知道每个分区的数据存储在哪里,以及每个分区的数据大小。这对于后续的 shuffle 读取操作至关重要,因为 reduce 任务需要知道从哪里读取数据。
也即是,前一个stage写数据确定分区是通过分区器,而后一个stage读数据确定分区是通过MapStatus。
SortShuffleWriter
|
|
- 初始化一个sorter,如果map侧(上一个stage)需要聚合,那么就创建带
aggregater并按键排序的sorter,否则创建一个不带aggregater的sorter; - 创建一个shuffleMapOutputWriter,写入器开启一个输出流,然后将给定reduce任务分区id的字节流持久化;
Creates a writer that can open an output stream to persist bytes targeted for a given reduce partition id. The chunk corresponds to bytes in the given reduce partition. This will not be called twice for the same partition within any given map task. The partition identifier will be in the range of precisely 0 (inclusive) to numPartitions (exclusive), where numPartitions was provided upon the creation of this map output writer via ShuffleExecutorComponents.createMapOutputWriter(int, long, int).
- 将记录写入sorter中,在sorter中经过处理后写出分区器分区后的数据
虽然叫sorter,但是如果map侧没有排序的需求,不会进行排序,如果map侧没有聚合的需求,也不会进行聚合。
什么时候会排序:sortByKey,sortBy
补充:
orderBy(SparkSQL中,RDD没有这个api):对 DataFrame 或 Dataset 进行全局排序。 类似于 SQL 中的 ORDER BY,会对整个数据集进行排序。 需要进行 shuffle 操作,以确保全局排序。
sortWithinPartitions:数据被写入 ExternalSorter,在内存中进行排序。 如果数据量超过内存限制,ExternalSorter 会将部分数据溢出到磁盘,并在需要时进行归并排序。 最终,排序后的数据被取出并生成新的 RDD。
什么时候会聚合:reduceByKey,combineByKey,aggregateByKey(map侧和reduce侧都进行聚合,支持不同的聚合操作),foldByKey(map侧和reduce侧聚合操作相同时等同于aggregateByKey)
注:map侧也叫分区内,reduce侧也叫分区间
- 向blockManager提交分区数据,并更新
MapStatus
选择策略
|
|
由源码可以看出,Spark的shuffle选择shuffleWriter的策略是匹配shuffleHandle,依次匹配SerializedShuffleHandle、BypassMergeSortShuffleHandle、BaseShuffleHandle。
而shuffleHandle的类型如下:
- SerializedShuffleHandle:适用于需要高效序列化的场景。通常与 UnsafeShuffleWriter 搭配使用。 这种 handle 主要用于 Spark 的 Tungsten 引擎优化路径,利用了 Spark 的内存管理和序列化优化。
- BypassMergeSortShuffleHandle:适用于小规模 shuffle 操作,特别是当分区数较少时。 通常与 BypassMergeSortShuffleWriter 搭配使用。 这种 handle 通过绕过排序步骤来提高性能,适合分区数小于 spark.shuffle.sort.bypassMergeThreshold 的情况。
- BaseShuffleHandle:这是一个通用的 handle 类型,适用于大多数 shuffle 操作。 通常与 SortShuffleWriter 搭配使用。 适合需要排序的 shuffle 操作。
选择策略
- 依赖类型: Spark 的 shuffle 依赖(ShuffleDependency)在 RDD 的转换操作中被创建。 依赖类型决定了 shuffle 的处理方式。例如,ShuffleDependency 中的 serializer 和 partitioner 会影响 ShuffleHandle 的选择。
- 配置参数: spark.shuffle.sort.bypassMergeThreshold: 这个参数决定了是否使用 BypassMergeSortShuffleHandle。如果分区数小于这个阈值,Spark 会选择 BypassMergeSortShuffleHandle。 spark.shuffle.manager: 这个参数可以配置 shuffle 的管理方式,影响 ShuffleHandle 的选择。
相关代码位于org.apache.spark.internal.config.package.scala1497行
|
|
- 数据规模和分区数: 小规模数据和少量分区通常会使用 BypassMergeSortShuffleHandle。 大规模数据和大量分区通常会使用 SerializedShuffleHandle 或 BaseShuffleHandle。
ShuffleReader
|
|
Spark的shuffleReader比起shuffleWriter来说就简单很多,只有一个BlockStoreShuffleReader子类。
- ShuffleHandle 转换:ShuffleHandle 被转换为 BaseShuffleHandle,以便访问 shuffle 依赖的详细信息。
- 获取块地址和批量获取能力: 代码检查是否完成了 shuffle 合并(isShuffleMergeFinalizedMarked)。 如果合并已完成,使用推送式 shuffle 方法 getPushBasedShuffleMapSizesByExecutorId 获取块大小和批量获取能力。 否则,使用常规方法 getMapSizesByExecutorId 获取块地址。
- 创建 BlockStoreShuffleReader: 使用获取的块地址和批量获取能力创建 BlockStoreShuffleReader。 shouldBatchFetch 参数决定是否启用批量获取,取决于 canEnableBatchFetch 和 canUseBatchFetch 的结果。
BlockStoreShuffleReader读数据流程:
- 初始化
- 获取数据块:
创建
ShuffleBlockFetcherIterator实例,用于从其他节点获取数据块。 该迭代器负责处理数据块的网络传输、反序列化和错误处理。 支持批量获取连续的数据块(如果条件允许),以提高网络传输效率。 - 反序列化:
使用
serializerManager.wrapStream包装从网络获取的输入流。 使用serializerInstance.deserializeStream将流反序列化为键值对迭代器。 - 聚合(可选):
如果
dep.aggregator被定义,使用聚合器对数据进行聚合。 如果mapSideCombine为 true,则数据已经在 map 端部分聚合,使用 combineCombinersByKey。 否则,使用 combineValuesByKey 进行聚合。 - 排序(可选):
如果
dep.keyOrdering被定义,使用 ExternalSorter 对数据进行排序。 ExternalSorter 可以处理大规模数据集,通过将数据溢出到磁盘来进行排序。 - 迭代器包装: 使用 InterruptibleIterator 包装最终的结果迭代器,以支持任务取消。 确保在任务取消时能够及时中断数据处理。
- 结果返回: 返回一个 Iterator[Product2[K, C]],包含所有读取和处理后的键值对