前置条件
需要部署好Hadoop集群和zookeeper集群
上传软件包
下载hbase包,上传到虚拟机或者服务器中。放在适合的位置。我放在了/usr/local/下
下载链接:https://archive.apache.org/dist/hbase/2.6.2/hbase-2.6.2-bin.tar.gz
修改配置文件
修改hbase/conf下的hbase-env.sh和habse-site.xml
在hbase-env.sh末尾添加export HBASE_MANAGES_ZK=false。
hbase-site.xml修改为如下内容,记得将主机名修改为自己的机器名。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:8020/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
</configuration>
|
修改环境变量
1
2
3
4
5
6
|
sudo vim ~/.bashrc
# 添加如下内容,记得将路径改为自己的hbase路径
#HBASE_HOME
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
|
解决hbase和Hadoop的log4j兼容问题
修改HBase的jar包,使用Hadoop的jar包
1
|
mv /usr/local/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /usr/local/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak
|
分发hbase
创建分发脚本xsync
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
cd
mkdir bin
cd bin
sudo vim xsync
# 添加如下内容
#!/bin/bash
#校验参数是否合法
if(($#==0))
then
echo 请输入要分发的文件!
exit;
fi
#获取分发文件的绝对路径
dirpath=$(cd `dirname $1`; pwd -P)
filename=`basename $1`
echo 要分发的文件的路径是:$dirpath/$filename
#循环执行rsync分发文件到集群的每条机器
for((i=1;i<=3;i++))
do
echo ---------------------hadoop$i---------------------
rsync -rvlt $dirpath/$filename hadoop$i:$dirpath
done
#此脚本用于虚拟机之间通过scp传送文件
|
添加执行权限,分发hbase
1
2
|
sudo chmod 777 xsync
xsync /usr/local/hbase
|
启动hbase
启动zookeeper成功之后再启动habse。
单点启动:
1
2
|
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
|
群启:bin/start-habse.sh
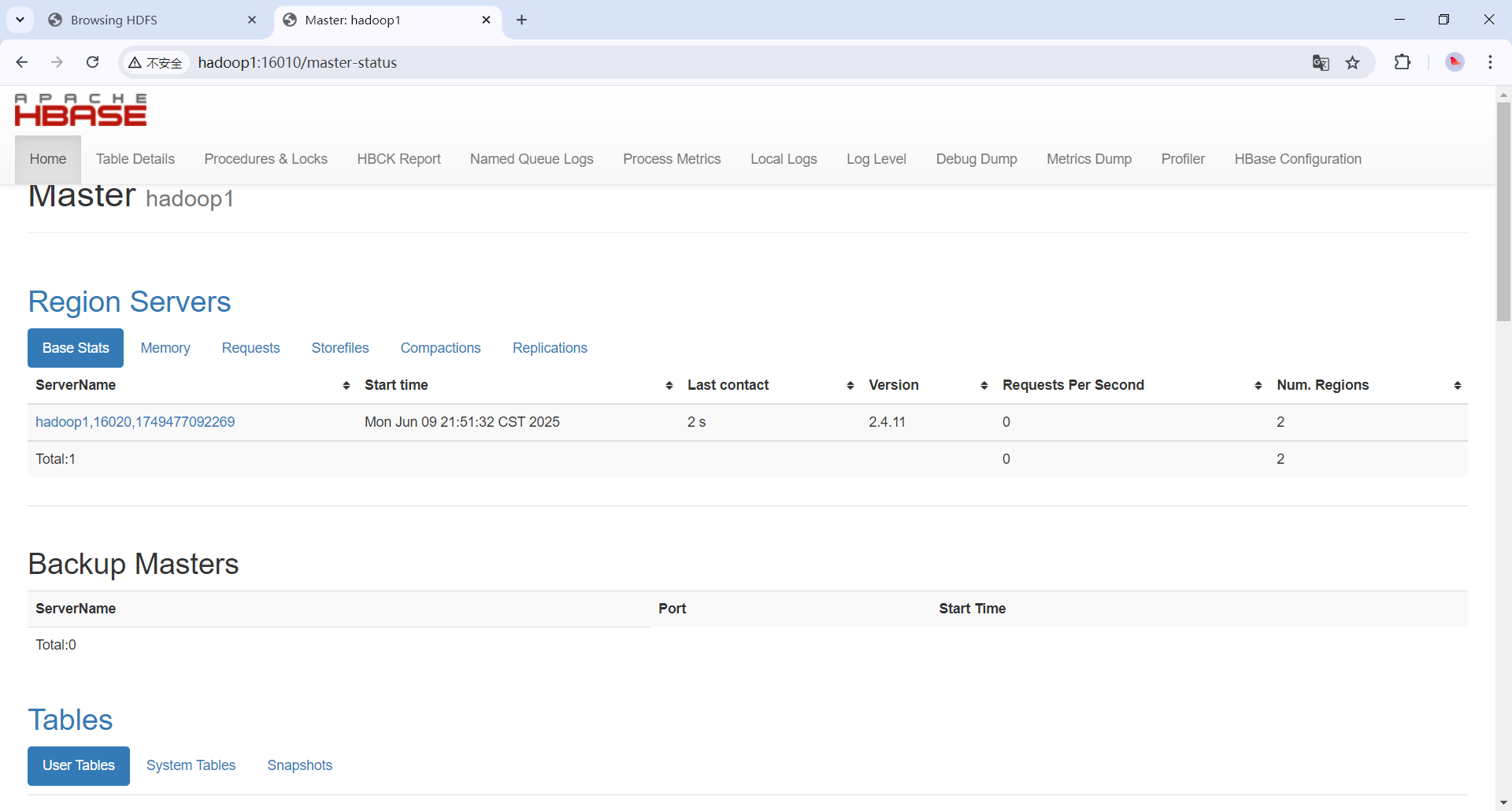
访问webui
http://hadoop1:16010/
能正常访问即成功。