前置准备:配置Hive的MySQL连接用户
MySQL的配置可参考我的教程 MySQL安装教程
- 创建Hive元数据库
1
|
create database metastore;
|
- 创建用户hive,设置密码为123456
1
2
3
|
create user 'hive'@'%' identified by '123456';
grant all privileges on metastore.* to 'hive'@'%' with grant option;
flush privileges;
|
安装Hive
参考资料:B站尚硅谷
062.Hive的安装部署_哔哩哔哩_bilibili
- 下载Hive安装包
注意:apache原装的Hive只支持Spark2.3.0,不支持Spark3.3.0,需要重新编译Hive的源码,尚硅谷已经编译好了,这里我就直接使用了
- 修改配置文件(cd 到hive下的conf文件夹,这里我已经将Hive安装包改名为hive并移动到/usr/local/下)
1
2
|
sudo mv hive-default.xml.template hive-default.xml
sudo vim hive-site.xml
|
将以下内容写入文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop1:3306/metastore?useUnicode=true&characterEncodeing=UTF-8&allowPublicKeyRetrieval=true&useSSL=false&serverTimezone=GMT</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop1:9083</value>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop1</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- hiveserver2的高可用参数,开启此参数可以提高hiveserver2的启动速度 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
|
- 配置环境变量
在下面添加
1
2
|
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
|
启动Hive
- 启动Hadoop
- 初始化Hive
1
2
|
cd /usr/local/hive
./bin/schematool -dbType mysql -initSchema
|
正常初始化会日志刷屏并出现大片空白,然后最后一行出现succeed或者complete的字样
如果没有正常初始化就复制最下面几行中的报错信息,粘贴到必应进行查找
- 启动Hive
启动Hive前需要先启动Hive的元数据库metastore和hiveserver2
注意:这里的metastore和hiveserver2每个都要单独开启一个终端,开启一个后再开一个新的终端进行命令
日志被重定向到了logs文件夹下,需要查看日志可以在这个文件夹下查看
1
2
3
|
cd /usr/local/hive/
hive --service metastore >logs/metastore.log 2>&1
hive --service hiveserver2 >logs/hiveServer2.log 2>&1
|
正常启动会出现一个交互界面如下:
- 解决Hive shell中打印大量日志的问题
当在Hive的命令行中查询时出现大量日志时,可以在conf下新建日志配置文件如下
1
2
|
cd /usr/local/hive/conf/
vim log4j.properties
|
粘贴如下内容
1
2
3
4
|
log4j.rootLogger=WARN, CA
log4j.appender.CA=org.apache.log4j.ConsoleAppender
log4j.appender.CA.layout=org.apache.log4j.PatternLayout
log4j.appender.CA.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
|
Hive on Spark配置
- 在官网下载纯净版Spark(不带Hadoop依赖的)
http://spark.apache.org/downloads.html
- 解压Spark
1
2
|
tar -zxvf spark-3.3.1-bin-without-hadoop.tgz -C /usr/local/
mv /usr/local/spark-3.3.1-bin-without-hadoop /usr/local/spark
|
- 修改spark-env.sh配置文件
1
2
|
mv /usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh
vim /usr/local/spark/conf/spark-env.sh
|
增添下面内容
1
|
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
|
- 配置Spark环境变量
添加下列内容
1
2
|
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
|
- 在Hive中创建spark配置文件
1
|
vim /usr/local/hive/conf/spark-defaults.conf
|
添加如下内容
1
2
3
4
5
|
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop1:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
|
在HDFS中创建如下路径,用于存储历史日志
1
|
hadoop fs -mkdir /spark-history
|
- 向HDFS上传Spark纯净版jar包
说明1:采用Spark纯净版jar包,不包含hadoop和hive相关依赖,能避免依赖冲突。
说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到
1
2
|
hadoop fs -mkdir /spark-jars
hadoop fs -put /usr/local/spark/jars/* /spark-jars
|
- 修改hive-site.xml文件
1
|
vim /usr/local/hive/conf/hive-site.xml
|
添加如下内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop1:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>30000ms</value>
</property>
|
Hive on Spark测试
- 启动hive客户端
1
2
|
cd /usr/local/hive/
bin/hive
|
- 创建一张测试表
1
|
hive (default)> create table student(id int, name string);
|
- 通过insert测试效果
1
|
hive (default)> insert into table student values(1,'abc');
|
结果如下则配置成功
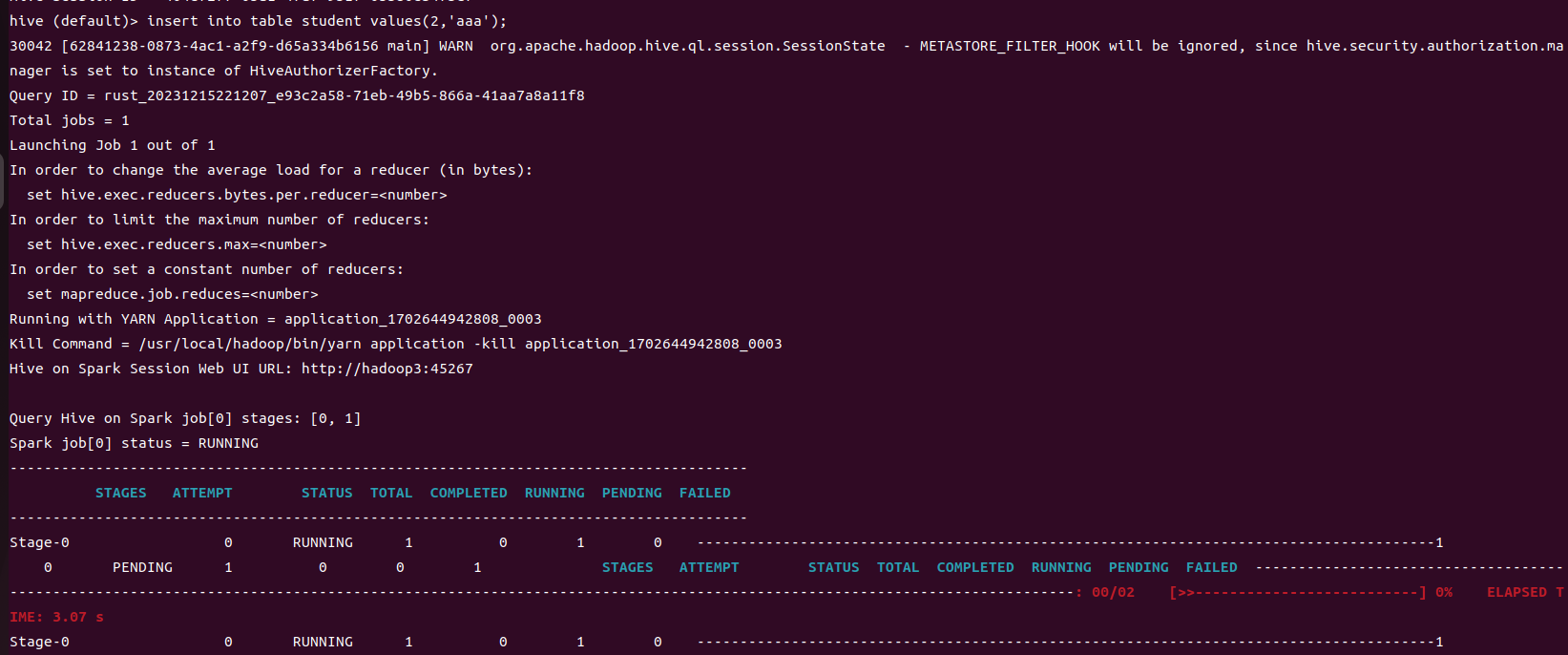
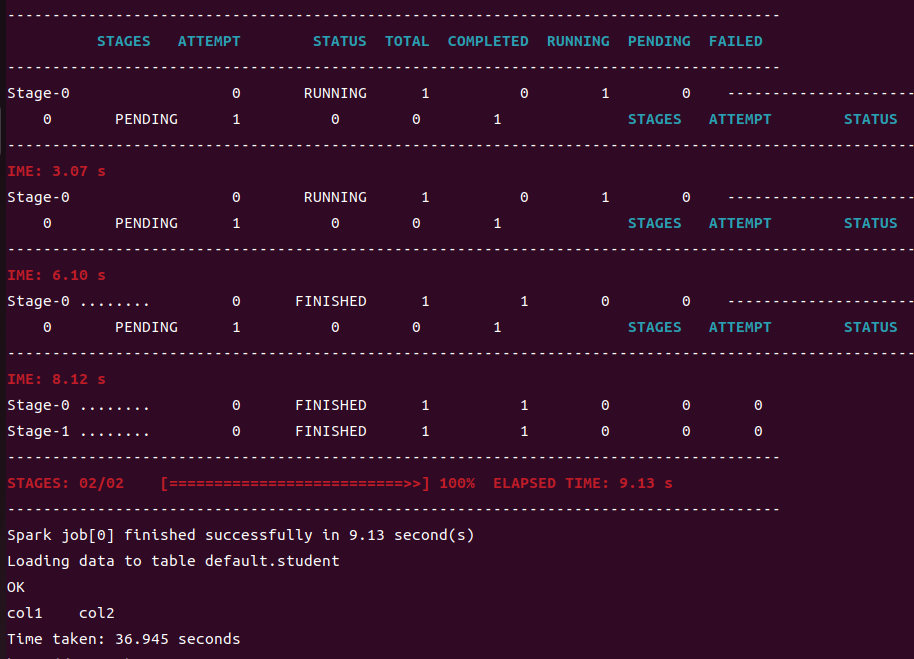
Yarn环境配置
增加ApplicationMaster资源比例
容量调度器对每个资源队列中同时运行的Application Master占用的资源进行了限制,该限制通过yarn.scheduler.capacity.maximum-am-resource-percent参数实现,其默认值是0.1,表示每个资源队列上Application Master最多可使用的资源为该队列总资源的10%,目的是防止大部分资源都被Application Master占用,而导致Map/Reduce Task无法执行。
生产环境该参数可使用默认值。但学习环境,集群资源总数很少,如果只分配10%的资源给Application Master,则可能出现,同一时刻只能运行一个Job的情况,因为一个Application Master使用的资源就可能已经达到10%的上限了。故此处可将该值适当调大。
- 在hadoop1的/usr/local/hadoop/etc/hadoop/capacity-scheduler.xml文件中修改如下参数值
1
|
vim capacity-scheduler.xml
|
1
2
3
4
|
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value>
</property
|
- 分发capacity-scheduler.xml配置文件
1
|
xsync capacity-scheduler.xml
|
- 重启集群
1
2
|
stop-all.sh
start-all.sh
|