Spark启动方式有:local模式、standalone模式、Yarn模式、K8S和Mesos模式,本教程只涉及前三种模式,另外两种可以自行查找资料。
Local模式
1.下载Spark
https://archive.apache.org/dist/spark/ 由于我的Hadoop版本是3.1.3,所以下载的Spark版本也是Spark3,这里下的是Spark3.3.1,只要是Spark3都可以和Hadoop3兼容。
2.解压Spark压缩包
解压Spark的压缩包,移动到/usr/local/下,修改文件夹的名字为spark
|
|
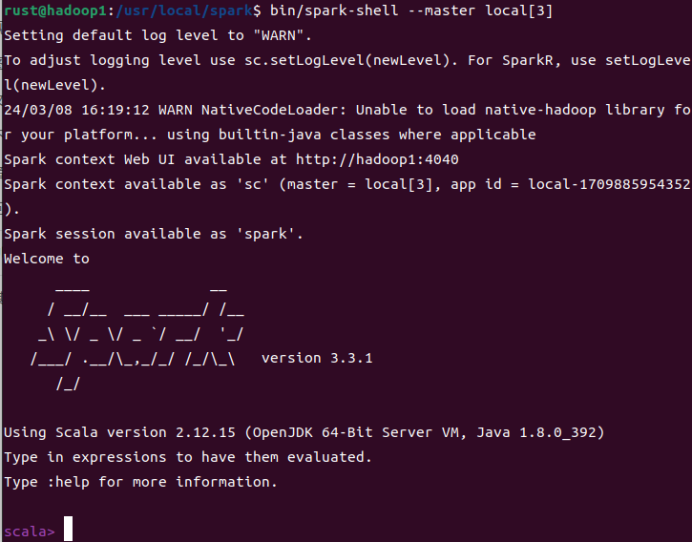
3.Local模式启动Spark
|
|
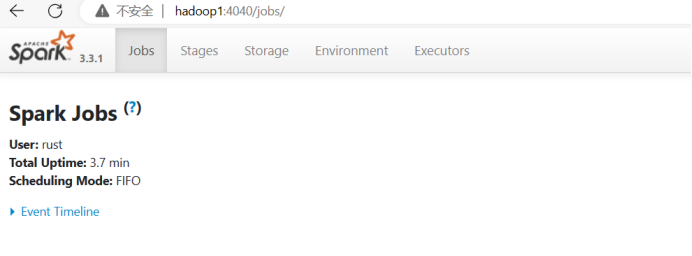
启动成功后,可以输入网址主机名:4040进行 Web UI 监控页面访问
Standalone模式
1.进入spark文件夹下的conf目录,修改workers.template文件名为workers
|
|
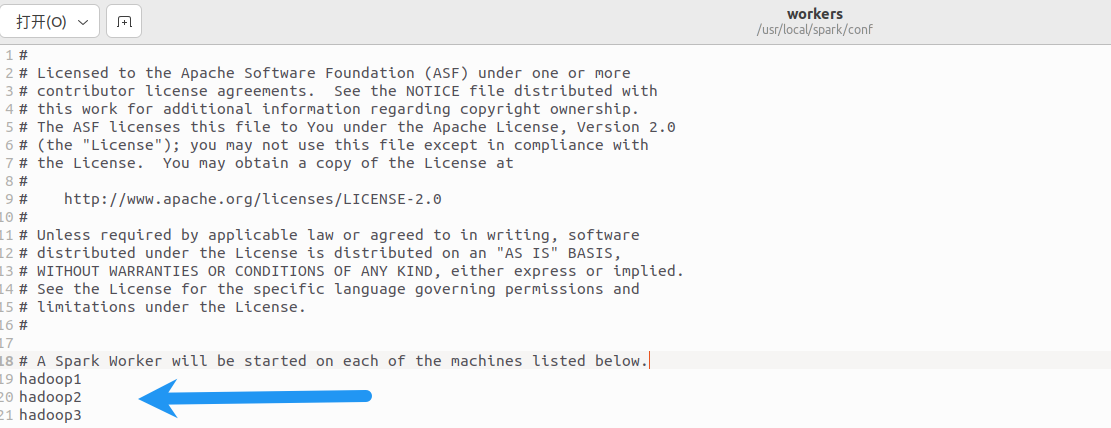
2.修改workers文件,添加worker节点
|
|

3.修改spark-env.sh.template文件名为spark-env.sh
4.修改spark-env.sh文件,添加JAVA_HOME环境变量和集群对应的master节点
![]()
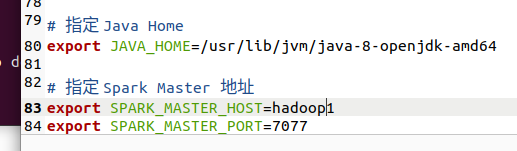 Java默认安装路径如下,手动安装的Java可以指定自己的Java路径
Java默认安装路径如下,手动安装的Java可以指定自己的Java路径
5.分发Spark
6.Standalone模式启动Spark集群
|
|
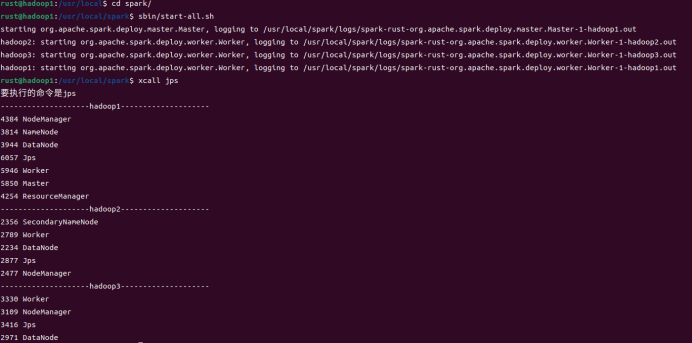
7.查看进程
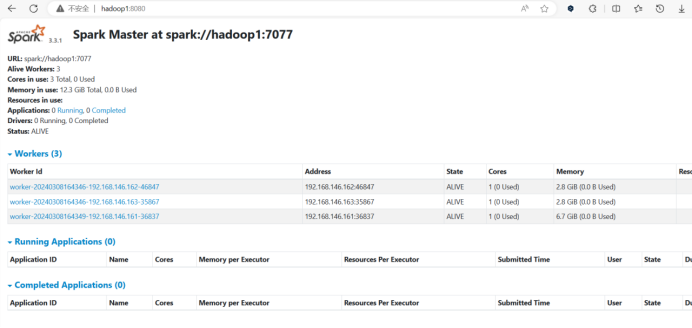
 Spark正常启动输入网址
Spark正常启动输入网址主机名:8080进行监控
8.提交应用测试Spark
|
|
注意:–master后面指定的主机名要改成自己的主机名(hadoop1改成自己的主机名)
指定的jar包要指定为自己的jar包,不同版本的示例jar包名字不同。
10是指当前应用的任务数量
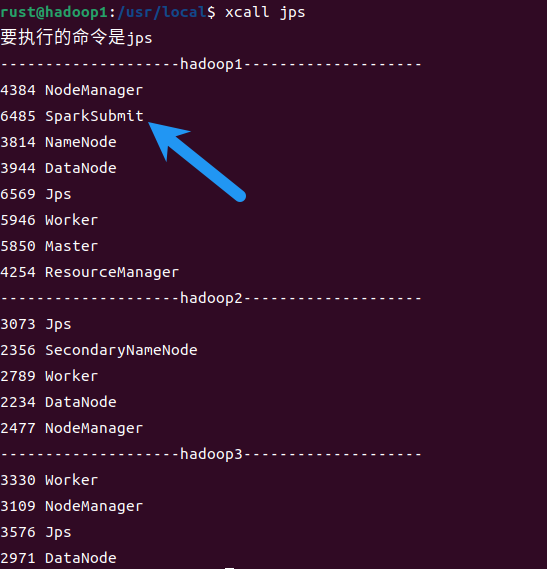
 提交任务时会有一个SparkSubmit进程,任务结束后进程停止
提交任务时会有一个SparkSubmit进程,任务结束后进程停止
Yarn 模式
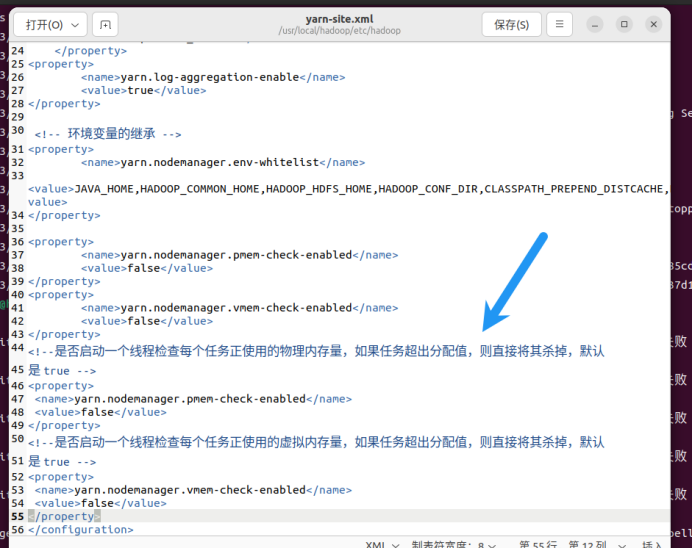
1.修改Hadoop配置文件
修改/usr/local/hadoop/etc/hadoop/yarn-site.xml, 并分发
|
|
|
|
 分发修改后的配置文件
分发修改后的配置文件
|
|
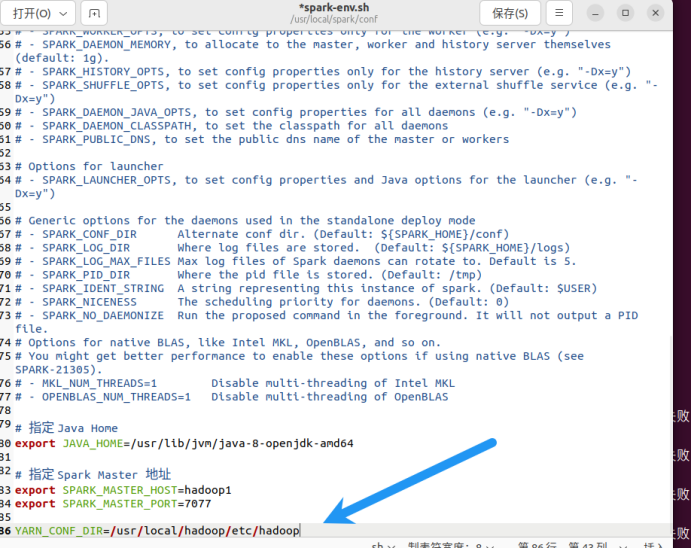
2. 修改conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
|
|
3.分发更改后的Spark-env.sh
|
|
4.Yarn模式提交任务测试
- Client模式
|
|

- Cluster模式
|
|

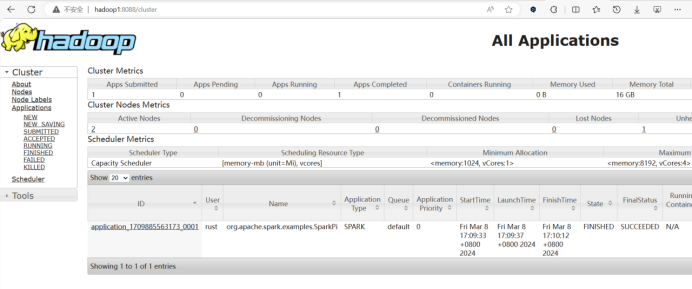
5.在hadoop1:8088查看,程序运行成功
补充:提交参数说明
| 参数 | 解释 | 可选值举例 |
|---|---|---|
| –class | Spark 程序中包含主函数的类 | |
| –master | Spark 程序运行的模式(环境) | 模式:local[*]、spark://hadoop1:7077、Yarn |
| –executor-memory 1G | 指定每个executor 可用内存为1G | 符合集群内存配置即可,具体情况具体分析。 |
| –total-executor-cores 2 | 指定所有executor使用的cpu核数析。为2个 | |
| –executor-cores | 指定每个executor使用的cpu核数 | |
| application-jar | 打包好的应用 jar,包含依赖。这个URL 在集群中全局可见。比如 hdfs:// 共享存储系统,如果是file:// path,那么所有的节点的 | |
| path 都包含同样的 jar | ||
| application-arguments | 传给 main()方法的参数 |