参考:尚硅谷Hadoop课程。
CSDN相关教程
在搭建Hadoop集群前需要先搭建好Ubuntu虚拟机,具体可参考下面的教程。
前置虚拟机搭建
本文搭建了三台虚拟机,其中hadoop1是主节点,主机名与ip对应关系如下。
如果你想抄我的配置,不想在部署的时候修改ip,你得先在vmvare里点击左上角编辑,虚拟网络编辑器。改成如下图所示。
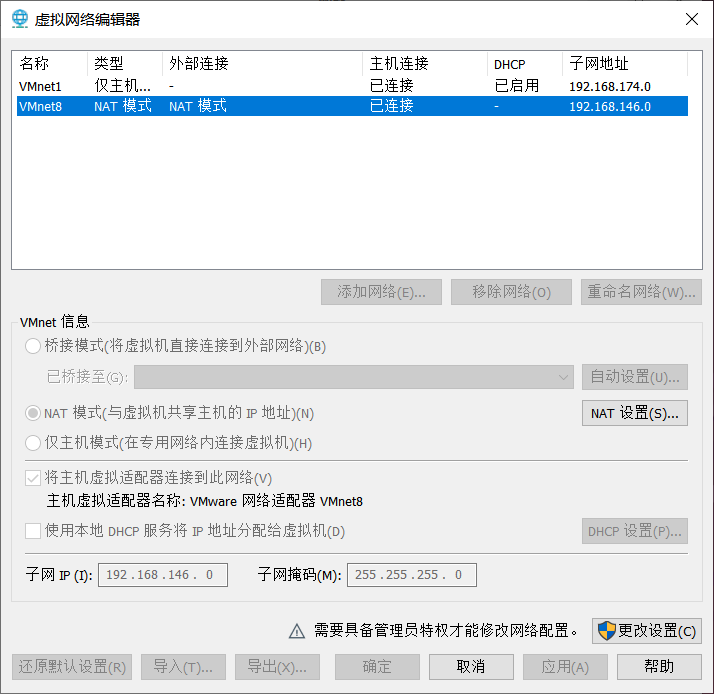
192.168.146.161 hadoop1
192.168.146.162 hadoop2
192.168.146.163 hadoop3
下载Hadoop
推荐在Hadoop官网下载。https://hadoop.apache.org/releases.html
可以在官网下载好后再用winscp/xshell等工具把Hadoop的二进制包上传到虚拟机上,也可以直接在虚拟机的下载路径(下载文件夹没有权限问题)直接下载Hadoop二进制包。命令如下:
1
2
|
cd ~/下载
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.4.1/hadoop-3.4.1.tar.gz
|
可以在这里直接右键提取到此处,然后右键改名为hadoop,也可以用命令解压后改名:
1
2
|
tar xzf hadoop-3.4.1.tar.gz
mv hadoop-3.4.1 hadoop
|
修改Hadoop配置文件
Hadoop的配置文件在Hadoop文件夹下的/etc/hadoop/。包含五个:
1
2
3
4
5
|
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
workers
|
照样可以右键修改,也可以用命令;
1
2
3
4
5
6
|
cd hadoop/etc/hadoop
vim core-site.xml
vim hdfs-site.xml
vim mapred-site.xml
vim yarn-site.xml
vim workers
|
依次添加配置信息(注意把用户名改成自己的用户名,我的用户名是rust)。core-site.xml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:8020</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>rust</value>
</property>
<property>
<name>hadoop.proxyuser.rust.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.rust.groups</name>
<value>*</value>
</property>
</configuration>
|
hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.http.address</name>
<value>hadoop1:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9868</value>
</property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.enable</name>
<value>true</value>
</property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policy</name>
<value>NEVER</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
|
mapred-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*</value>
</property>
</configuration>
|
yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
|
workers
1
2
3
|
hadoop1
hadoop2
hadoop3
|
修改hadoop-env.sh,添加java环境变量,这是用命令行apt安装的Java路径,如果自己的Java版本或者路径不对,请修改成自己的版本。
1
2
3
|
vim hadoop-env.sh
#添加如下内容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
|
修改后移动到配置文件中的位置(/usr/local/hadoop)。其他位置也可以,但是我习惯放在/usr/local下。如果想改到其他的目录记得修改上面的五个配置文件设计到的地方。
1
2
|
cd ~/下载
sudo mv hadoop /usr/local/
|
添加环境变量
修改环境变量,添加如下内容:
1
2
|
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
|
添加后使用hadoop version命令查看,如果出现Hadoop版本,那环境变量就修改成功了。如果没有,关闭当前的终端,新开一个终端试试。
如果还不行,复查一下前面的步骤哪里做的不对。
文件分发和命令传输的脚本
在用户目录创建一个bin目录,创建xcall(命令传输,用于在三台虚拟机上依次执行相同命令)、xsync(文件分发,用于把文件分发到三台虚拟机上)。
1
2
3
4
5
6
7
|
cd
mkdir bin
cd bin
vim xsync
sudo chmod 777 xsync
vim xcall
sudo chmod 777 xcall
|
xsync内容如下,注意我的三台虚拟机叫hadoop1、hadoop2、hadoop3。如果你的虚拟机不叫这个名字,记得修改成自己的主机名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#!/bin/bash
#校验参数是否合法
if(($#==0))
then
echo 请输入要分发的文件!
exit;
fi
#获取分发文件的绝对路径
dirpath=$(cd `dirname $1`; pwd -P)
filename=`basename $1`
echo 要分发的文件的路径是:$dirpath/$filename
#循环执行rsync分发文件到集群的每条机器
for((i=1;i<=3;i++))
do
echo ---------------------hadoop$i---------------------
rsync -rvlt $dirpath/$filename hadoop$i:$dirpath
done
#此脚本用于虚拟机之间通过scp传送文件
|
xcall内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#!/bin/bash
#在集群的所有机器上批量执行同一个命令
if(($#==0))
then
echo 请输入要操作的命令!
exit;
fi
echo 要执行的命令是$*
#循环执行此命令
for((i=1;i<=3;i++))
do
echo --------------------hadoop$i--------------------
ssh hadoop$i $*
done
#此脚本用于对所有声明的虚拟机进行命令的传输
|
配置hosts映射
修改/etc/hosts。添加映射
添加如下内容:记得把ip改成自己的ip,虚拟机看ip和改ip的教程在前置教程安装虚拟机里有写,也可以自行必应查询或者问大模型。
1
2
3
|
192.168.146.161 hadoop1
192.168.146.162 hadoop2
192.168.146.163 hadoop3
|
补充:配置Windows到虚拟机的hosts映射:(可选)
修改C盘下的hosts文件,路径为C:\Windows\System32\drivers\etc
克隆虚拟机
在终端命令中关闭虚拟机或者直接在关掉vmvare再启动。
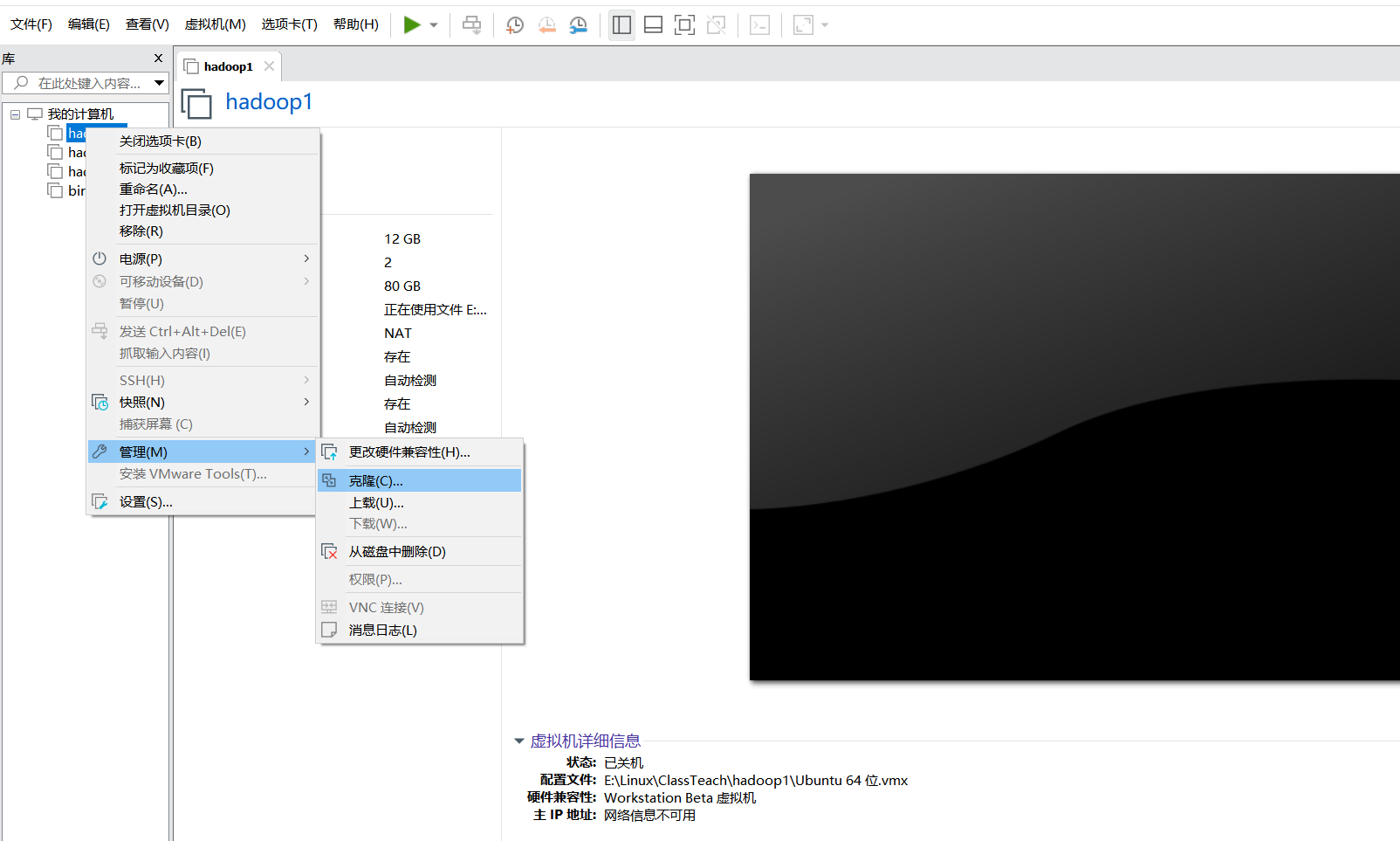
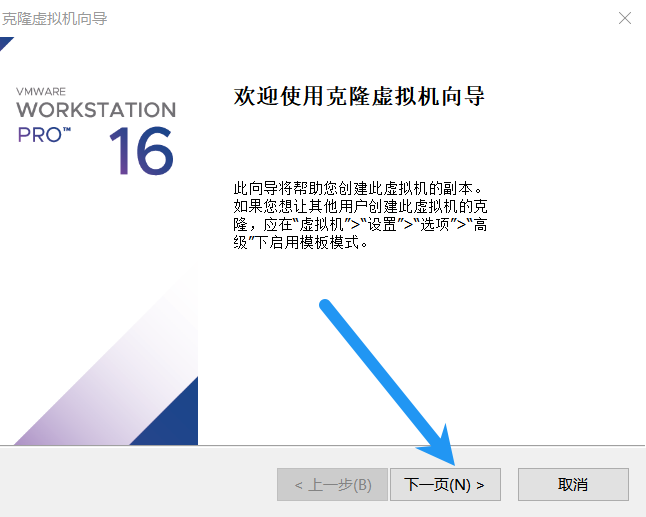
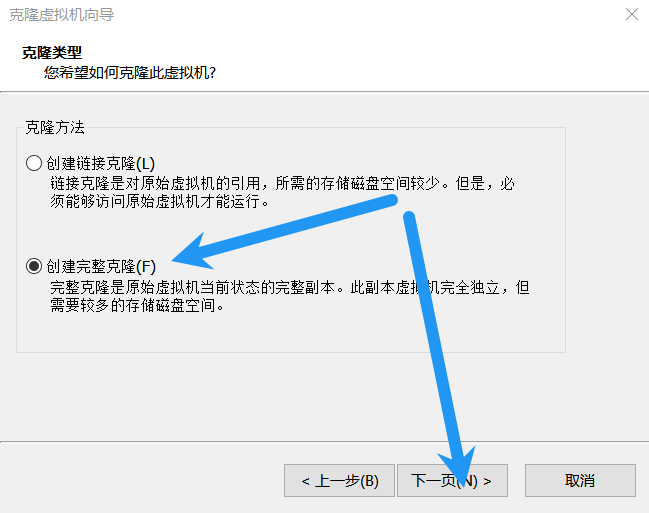
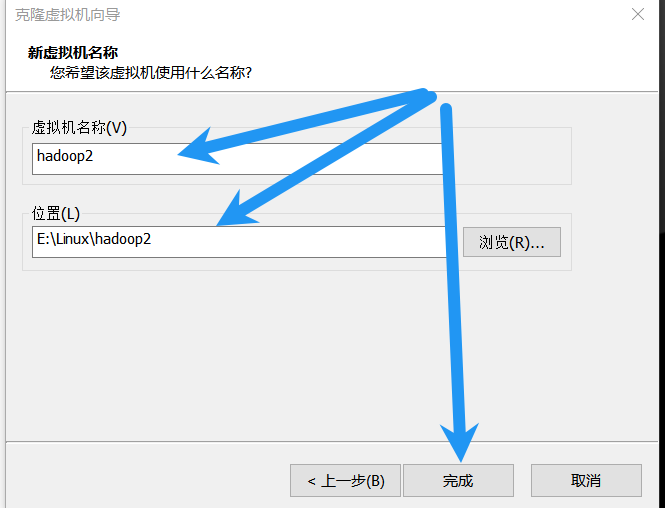 按照上面的步骤再克隆一台hadoop3。克隆完成后点击vmvare左上角的文件,打开。
按照上面的步骤再克隆一台hadoop3。克隆完成后点击vmvare左上角的文件,打开。
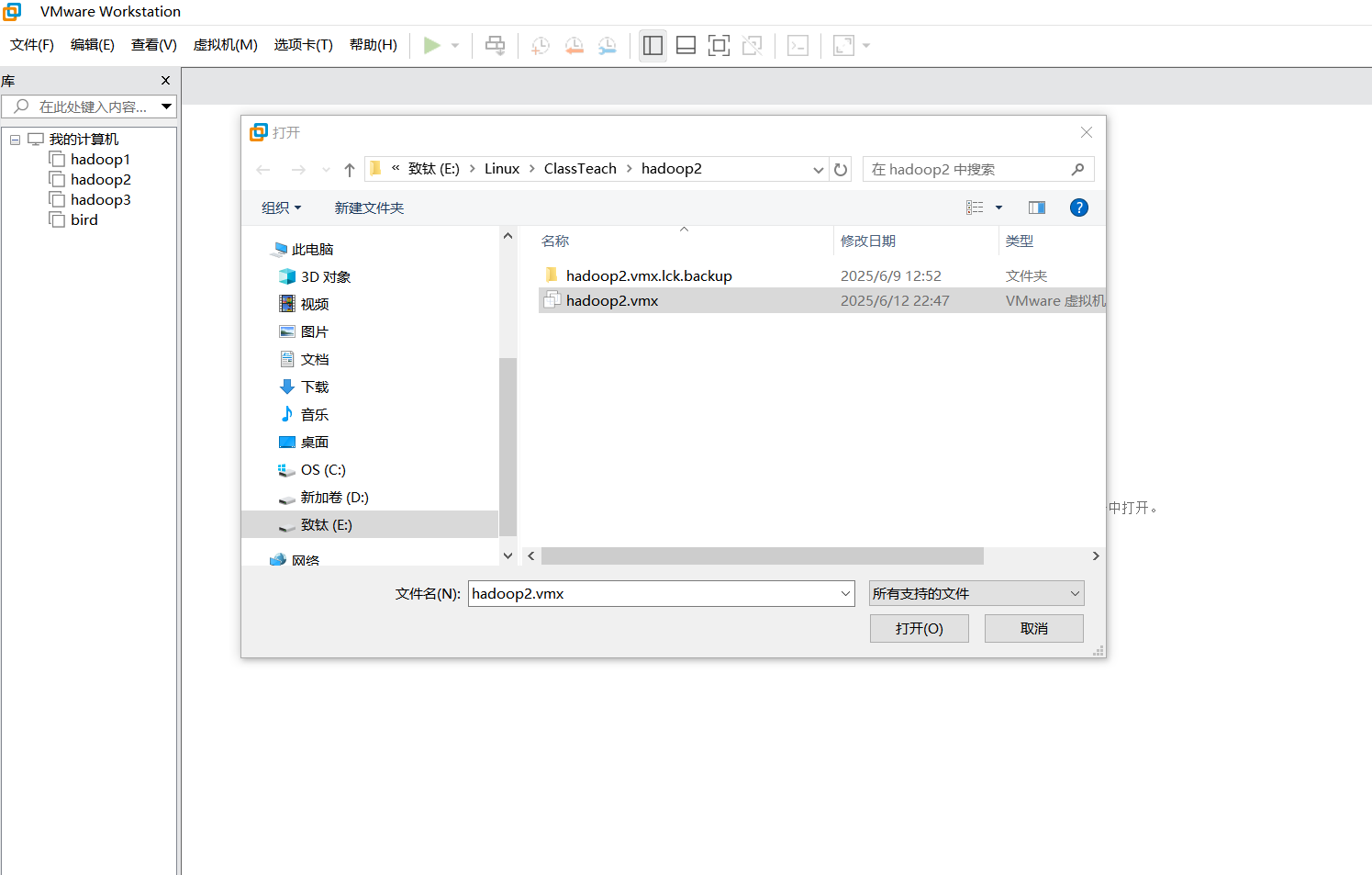
修改另外两台机主机名和ip
在另外两台机上分别执行sudo vim /etc/hostname,分别改成hadoop2和hadopp3。
修改网络,注意如果你之前改ip是用可视化界面改的就一定要用可视化界面改,如果之前是用命令改的那现在也要用命令改,不然会出问题,将无法访问外网。
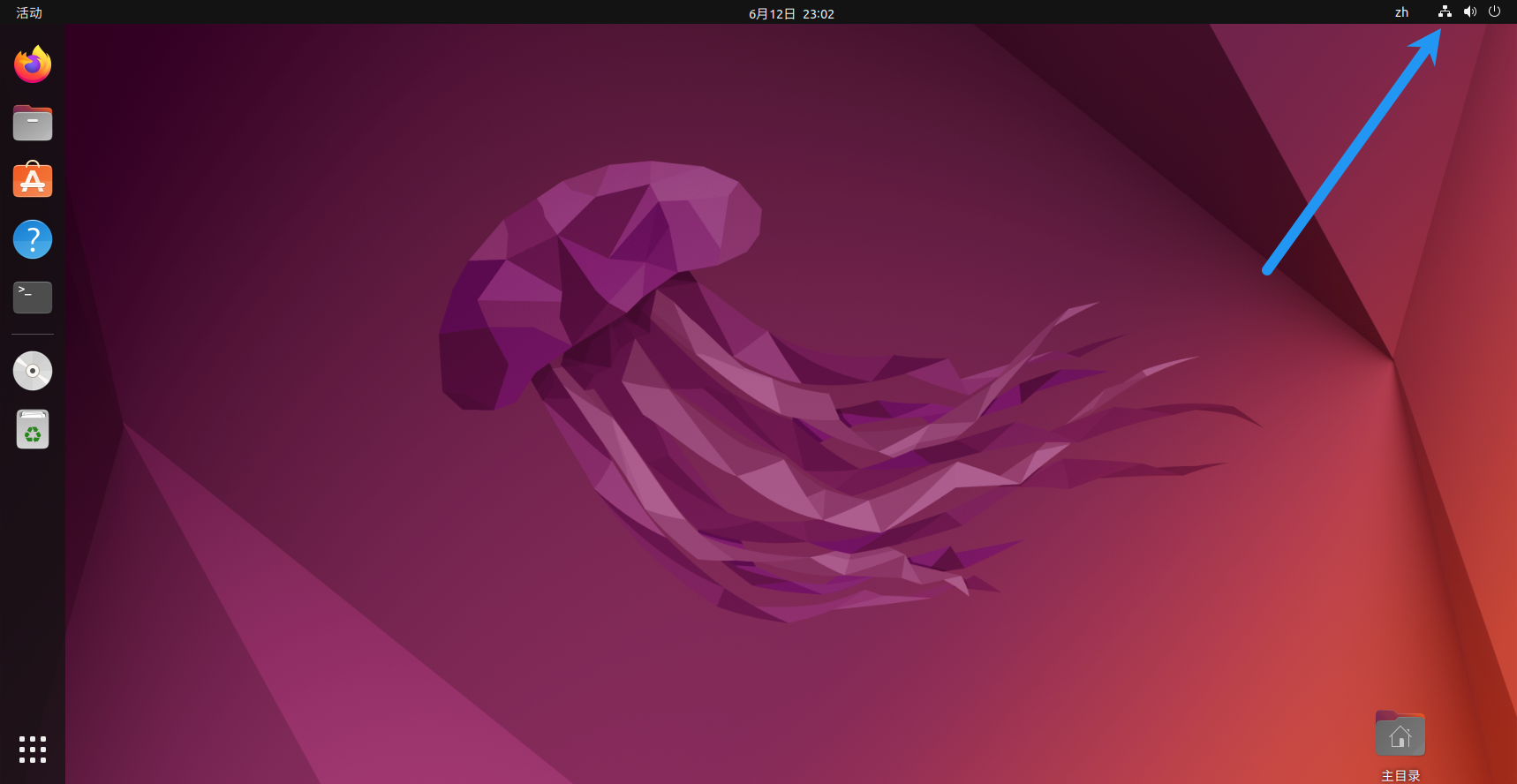
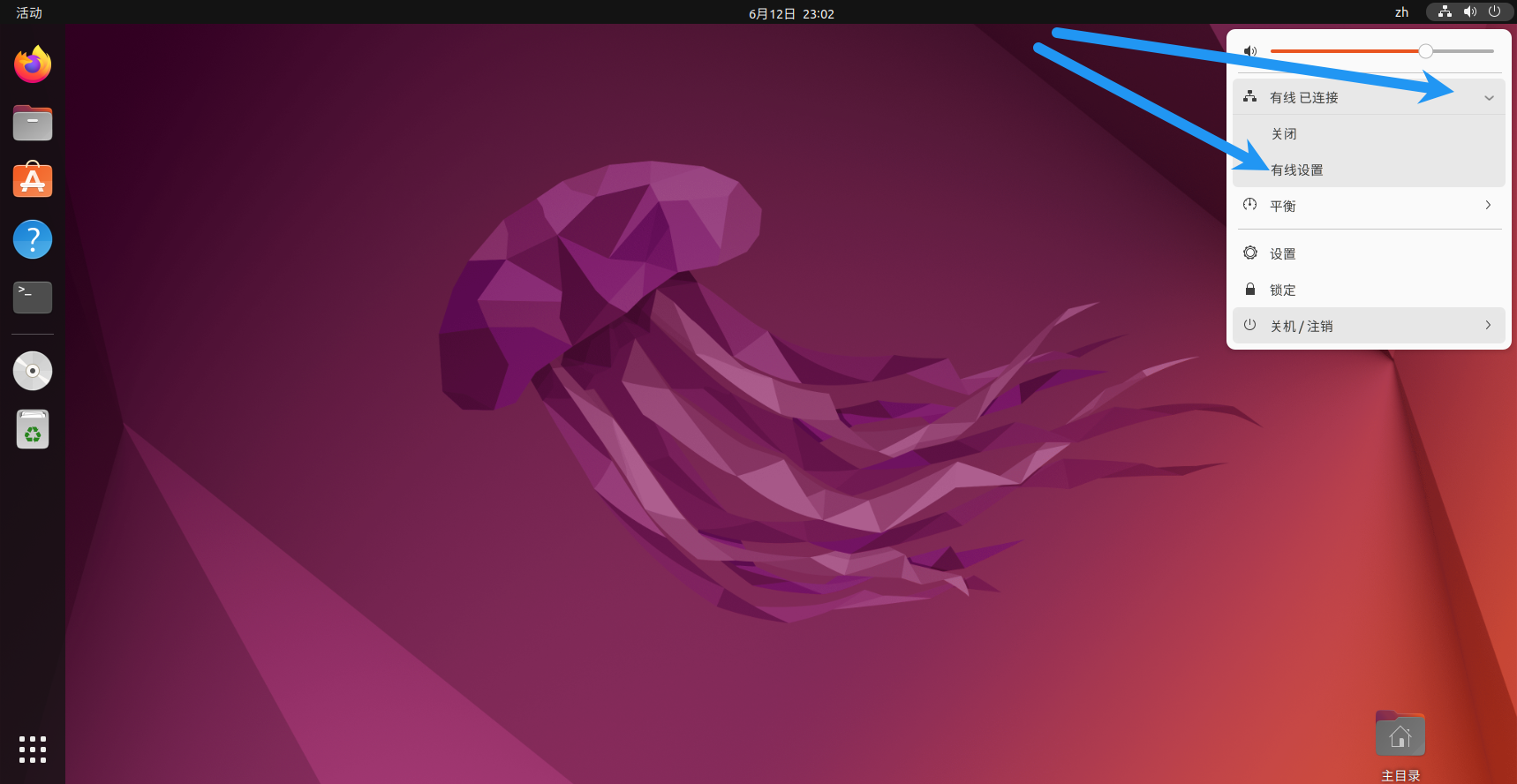
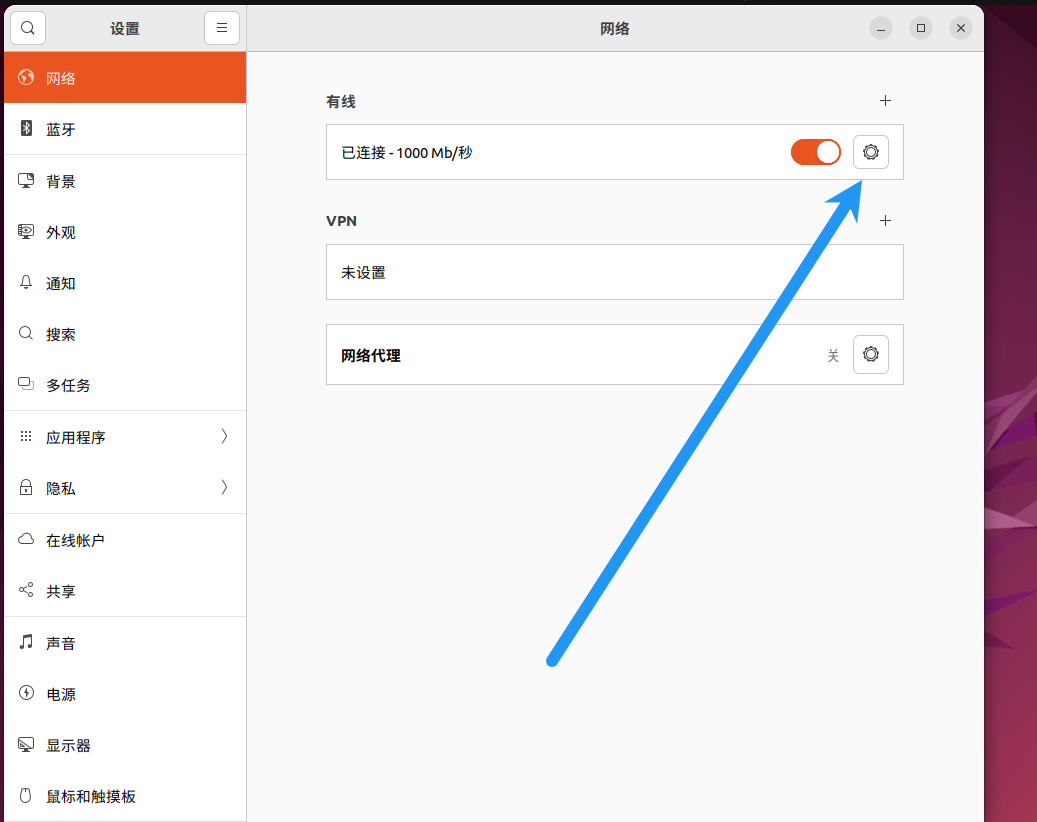
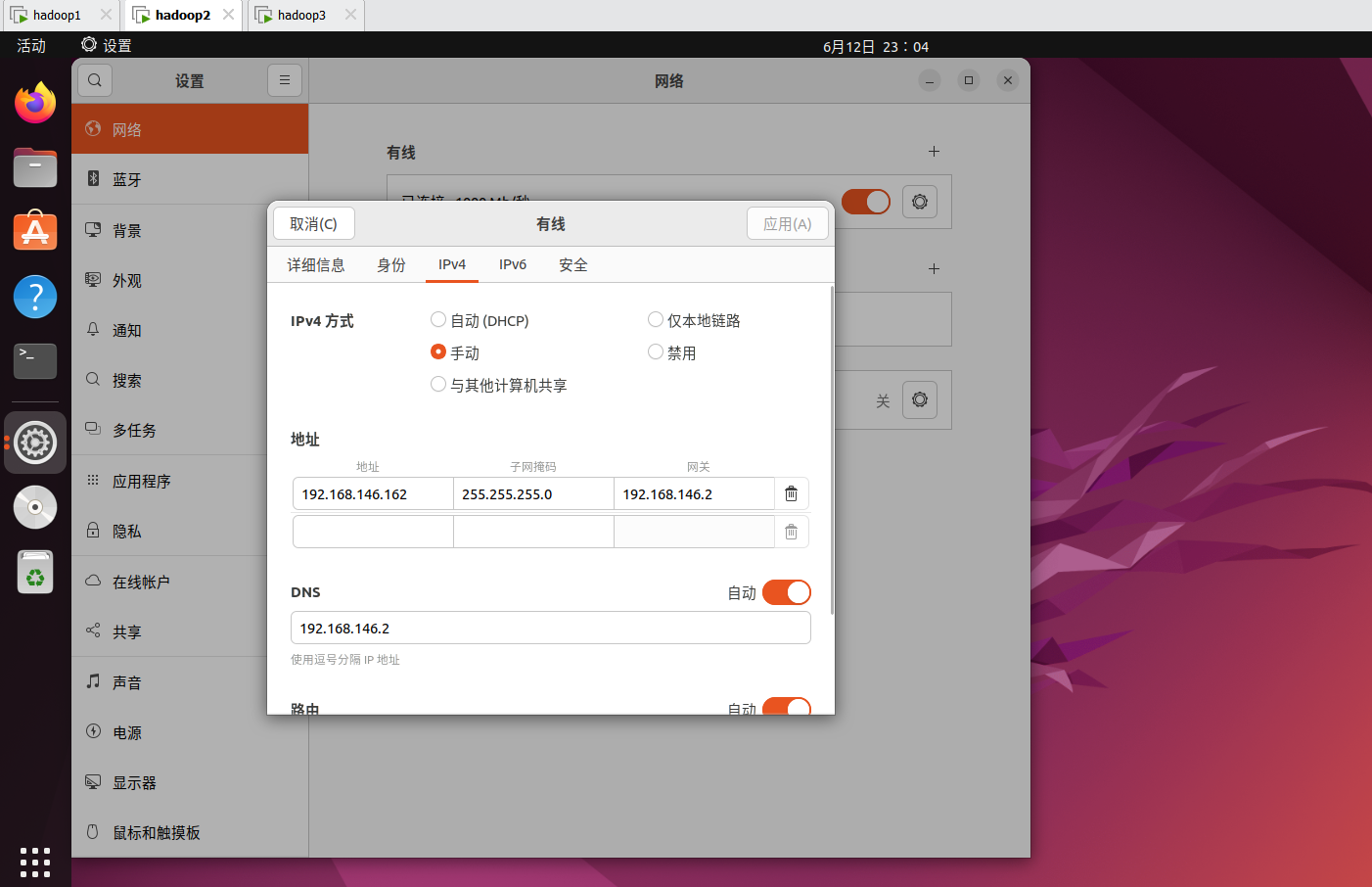 这里的ip改成之前hosts映射里写的ip。
这里的ip改成之前hosts映射里写的ip。
配置ssh免密登录
配置免密登录后就不用每次文件分发和命令传输就输一次密码。
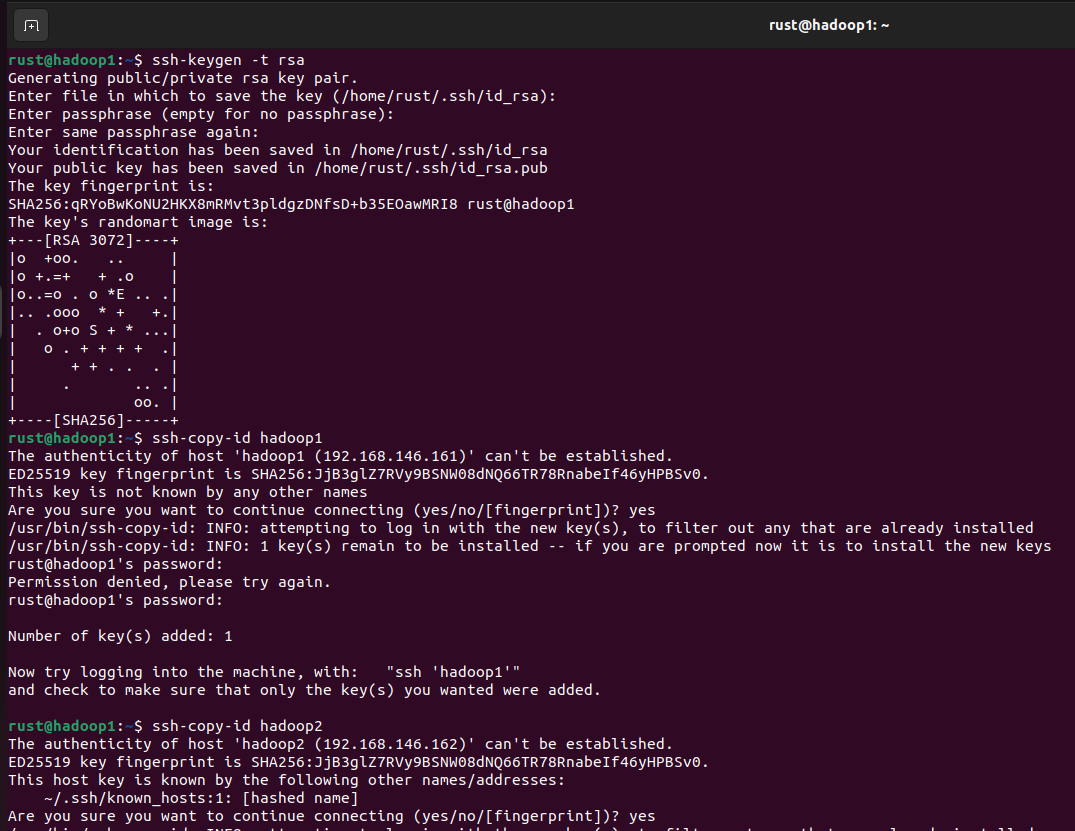
在hadoop1上执行如下密钥生成命令:
一直回车就行,然后再执行如下密钥拷贝命令:
1
2
3
|
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
|
如此hadoop1就可以免密登录另外两台机,如果想三台机相互可以免密登录,那分别在hadoop2和hadoop3上执行密钥拷贝命令即可。
测试免密情况,在hadoop1上执行如下命令:
初始化Hadoop并启动
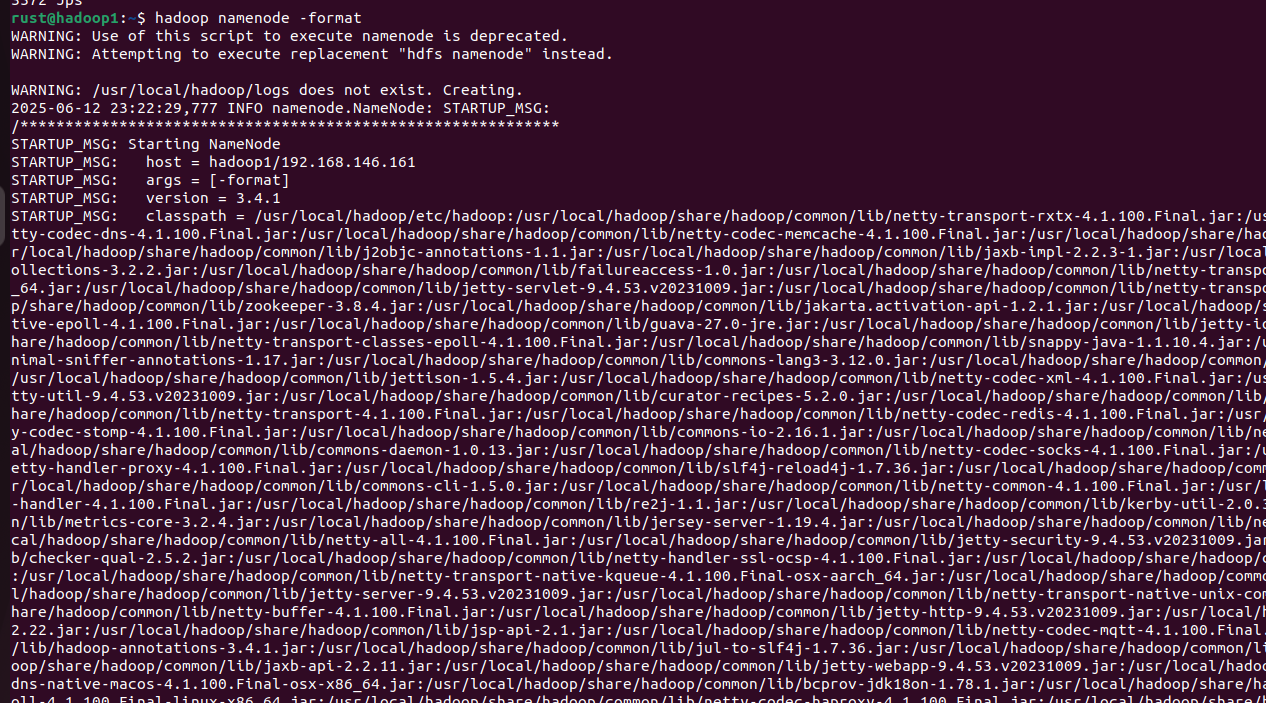
Hadoop初始化命令如下,在hadoop1上执行如下命令:
1
2
|
hadoop namenode -format
start-all.sh
|
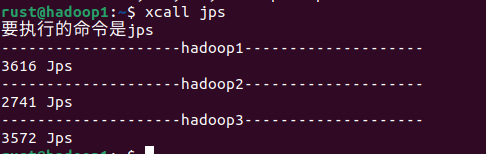
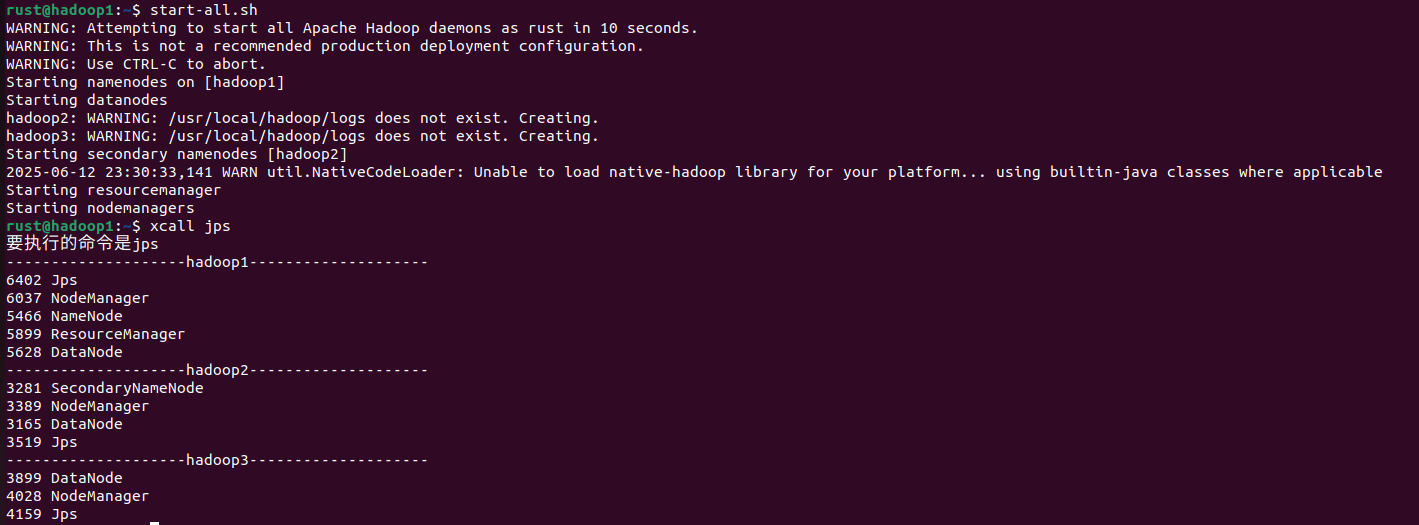 Hadoop启动后注意看jps进程,一定要有图中的进程,少一个就是安装失败了,请仔细核对一下自己前面的步骤哪里做的不对,尤其是Hadoop的五个配置文件和
Hadoop启动后注意看jps进程,一定要有图中的进程,少一个就是安装失败了,请仔细核对一下自己前面的步骤哪里做的不对,尤其是Hadoop的五个配置文件和hadoop-env.sh。
查看webui
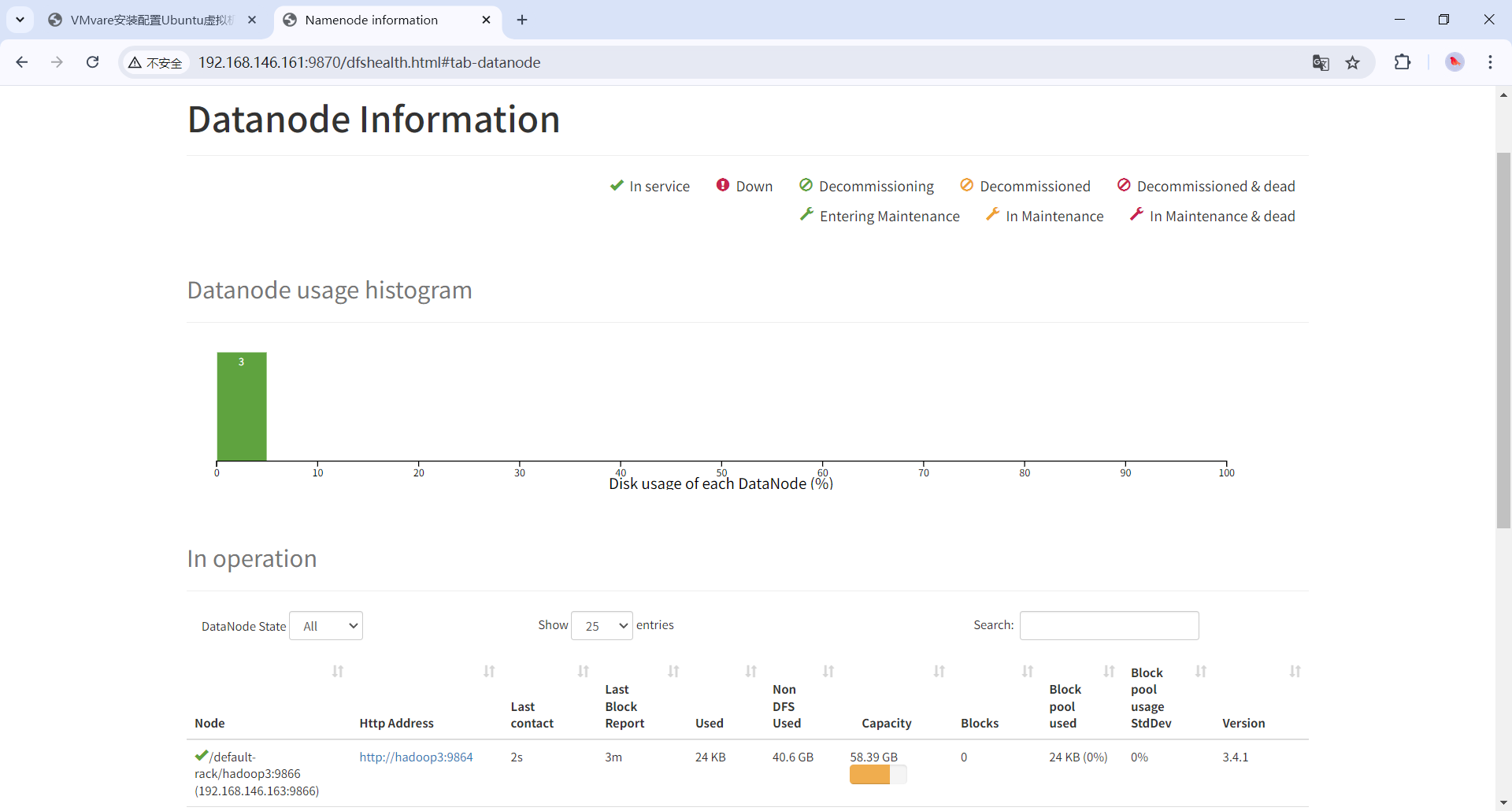
访问192.168.146.161:9870,看见有三个节点即是配置成功。在Windows配置hosts映射后也可以访问hadoop1:9870
补充:Ubuntu修改主机名后怎么办
-
修改hosts:sudo vim /etc/hosts
-
修改hostname:sudo vim /etc/hostname
-
修改 xsync xcall,把脚本里的旧的用户名改成新的用户名。比如主机名从hadoop01->hadoo1,那就要把脚本里的hadoop0$i改成hadoop$i。
-
修改ssh,直接删除旧的ssh密钥,重新生成拷贝,在主机执行如下命令(记得把主机名改成自己的)。
1
2
3
4
|
ssh-keygen -t rsa
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
|
5.修改Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、worker
删除hdfs的数据(/usr/local/hadoop/hdfs/),主机(namenode所在节点)会多一个name,从节点只有data,都删除,把tmp文件夹直接删掉。
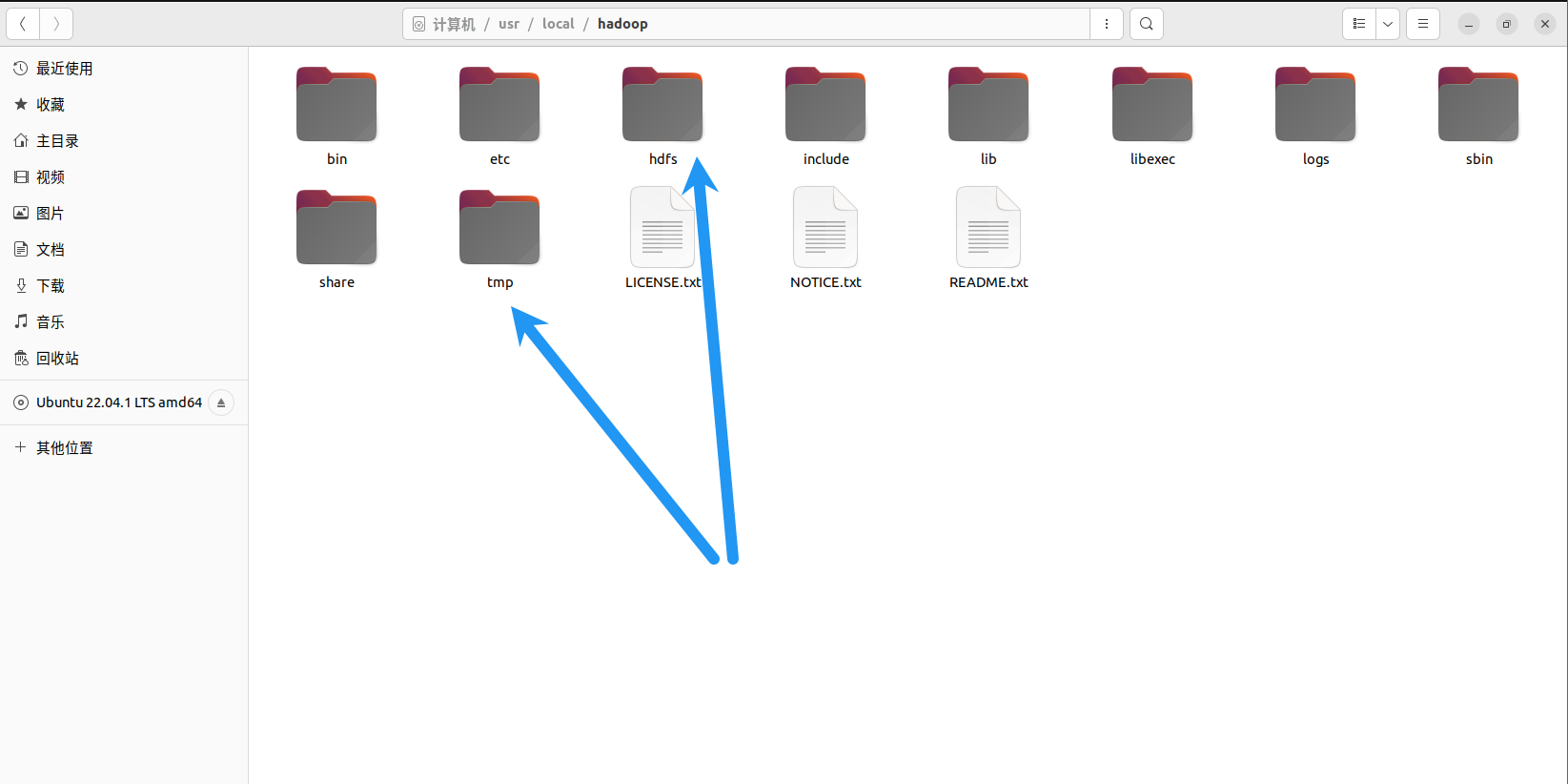
备忘录:如果安装了hive和spark,那还需要修改如下文件
hive-site.xml
修改spark/conf/worker
spark-env.sh
spark-defaults.conf